
Building a RAG Pipeline on Excel: Harnessing Qdrant and Open-Source LLMs for Stock Trading Data


Introduction
In today's data-driven world, Excel remains a cornerstone for businesses, containing invaluable insights within its spreadsheets. However, extracting meaningful information from these vast datasets can be time-consuming and requires specialized skills. This is where Retrieval Augmented Generation (RAG) comes into play.
RAG is a powerful approach that combines the strengths of large language models (LLMs) with the efficiency of information retrieval. By coupling these technologies, RAG enables machines to access and process information from various sources, including Excel, and generate human-quality text formats.
This blog will guide you through a RAG system specifically tailored for Excel data. We'll leverage the power of LlamaIndex and LlamaParse to transform your spreadsheets into a searchable knowledge base. We'll use LlamaParse to extract data from Excel files and store it efficiently in Qdrant for fast searching.
LlamaIndex
LlamaIndex is a data framework to bridge the gap between custom data sources and LLMs like Llama 3. It allows users to ingest data from various sources such as vector databases or files, and then indexes this data into intermediate representations. The user can then query their data in natural language and interact with it using chat interfaces.
LlamaIndex works by first indexing the data into a vector index during the indexing stage, which creates a searchable knowledge base specific to the domain. During the querying stage, the system searches for relevant information based on the user's query and then provides this information to the LLM to generate an accurate response. You can learn more about LlamaIndex here.
LlamaParse
LlamaParse is a powerful document-parsing platform designed to work seamlessly with LLMs. It is built to parse and clean data, ensuring high-quality inputs for downstream LLM applications like RAG. LlamaParse supports parsing PDFs, Excel, HTML, XML, and many other common document formats. You can learn more about LlamaParse here.
Qdrant
Qdrant is an open-source vector database and vector search engine which provides a fast and scalable vector similarity search service. It is designed to handle high-dimensional vectors for performance and massive-scale AI applications. You can learn more about the Qdrant vector database here.
Groq
Groq is an AI solutions company known for its cutting-edge technology, particularly the Language Processing Unit (LPU) Inference Engine, designed to enhance Large Language Models (LLMs) with ultra-low latency inference capabilities. Groq APIs enable developers to integrate state-of-the-art LLMs like Llama3 and Mixtral into applications. In our RAG pipeline, we will be using llama3-70b-8192 as the LLM model.
Building a RAG with Excel Data
We will construct a Retrieval Augmented Generation (RAG) system utilizing a stock trading dataset. The underlying data, housed in an Excel spreadsheet, encompasses open trade positions characterized by stock symbol, acquisition price, quantity, and purchase date. The RAG system will facilitate the extraction of critical metrics such as position count by stock, price distribution, and aggregate holding quantity.
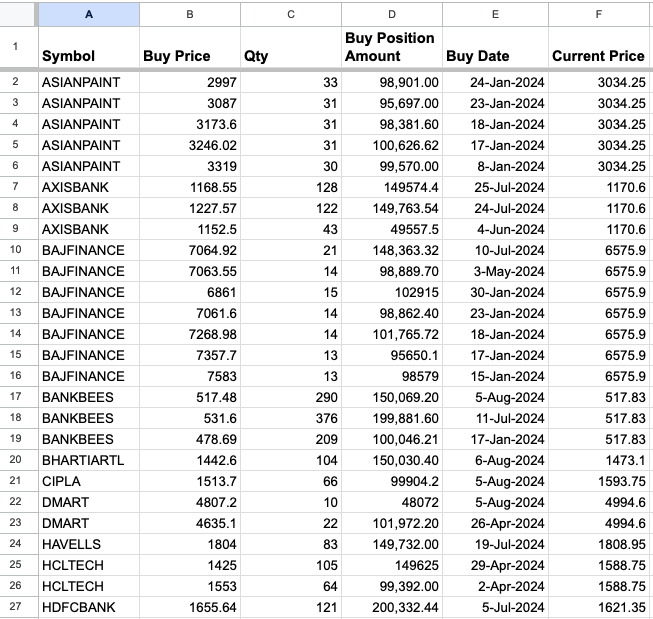
A visual representation of the Excel dataset is provided below.
Installing Dependencies
We will begin by installing the required dependencies.
!pip install llama-index llama-parse qdrant_client llama-index-vector-stores-qdrant llama-index-llms-groq fastembed llama-index-embeddings-fastembed
llama-indexis the core library for LlamaIndex.llama-parselibrary for parsing the Excel file.qdrant_clientandllama-index-vector-stores-qdrantare the 2 dependencies used for performing insert and fetch operations over the Qdrant DB.llama-index-llms-groqfor connecting to the Groq interface.fastembedandllama-index-embeddings-fastembedare required to generate embedding.
Next, we will create an instance of LlamaParser.
from llama_parse import LlamaParse
from google.colab import userdata
from llama_index.core import SimpleDirectoryReader
import nest_asyncio
nest_asyncio.apply()
parser = LlamaParse(
api_key=userdata.get('LLAMA_CLOUD_API_KEY'),
parsing_instruction = """You are parsing the open positions from a stock trading book. The column Symbol contains the company name.
Please extract Symbol, Buy Price, Qty and Buy Date information from the columns.""",
result_type="markdown"
)
When instantiating the LlamaParse object we have passed: parsing_instruction and result_type as the Parsing options.
In result_type we have specified the format of our output. By default, LlamaParse will return results as parsed text. The other options available are markdown, which formats the output as clean Markdown, and JSON which returns a data structure representing the parsed object. In parsing_instruction we can provide more context to LlamaParse on the data it is parsing. LlamaParse can use LLMs under the hood, allowing us to give it natural-language instructions about what it's parsing and how to parse.
Now let's load the Excel file and parse it using LlamaParser.
file_extractor = {".xlsx": parser}
documents = SimpleDirectoryReader(input_files=['my_report.xlsx'], file_extractor=file_extractor).load_data()
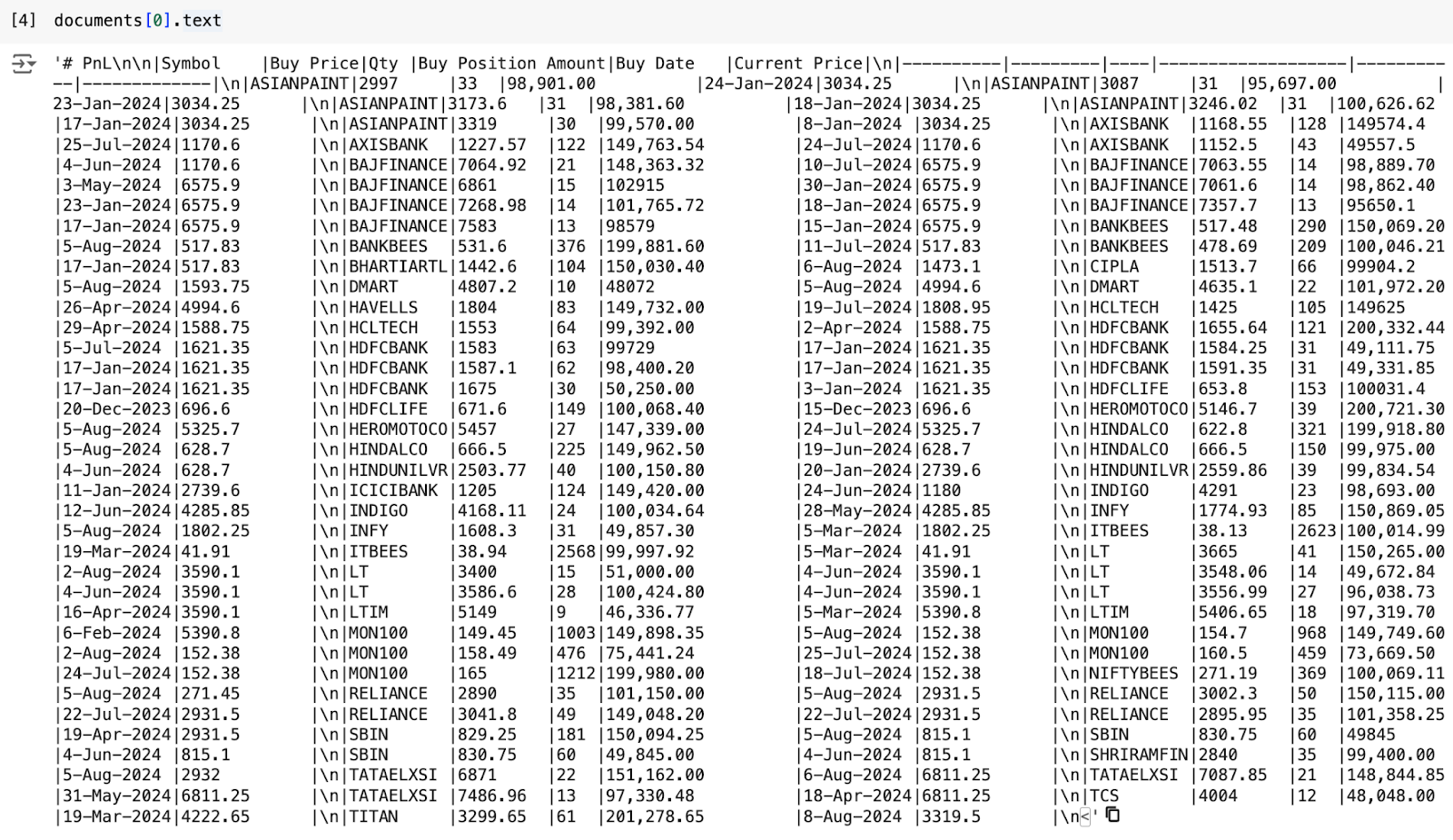
Since we have passed the result_type value as markdown, we got the parsed output in markdown format. Below is the parsed output.
Storing Excel Data in Qdrant
The parsed Excel data is now stored within the documents variable. Our next objective is to populate the Qdrant database with this information. To achieve this, we'll convert the documents into VectorStoreIndex. This index will subsequently be stored within the vector database. The underlying LLM model for this process is llama3-70b, interfaced through GROQ APIs. To generate embeddings, we've selected the bge-small-en-v1.5 model.
from llama_index.llms.groq import Groq
from llama_index.core import Settings
from llama_index.embeddings.fastembed import FastEmbedEmbedding
from google.colab import userdata
llm = Groq(model="llama3-70b-8192", api_key=userdata.get('GROQ_API_KEY'))
Settings.llm = llm
embed_model = FastEmbedEmbedding(model_name="BAAI/bge-small-en-v1.5")
Settings.embed_model = embed_model
To establish a connection to the Qdrant database, a Qdrant client instance is required. We will proceed to create this instance.
from qdrant_client import QdrantClient
from google.colab import userdata
QDRANT_URL = userdata.get('QDRANT_URL')
QDRANT_API_KEY = userdata.get("QDRANT_API_KEY")
qdrantClient = QdrantClient(
url=QDRANT_URL,
prefer_grpc=True,
api_key=QDRANT_API_KEY)
Now we will be calling the VectorStoreIndex method to store the index in Qdrant DB. The VectorStoreIndex takes Documents and splits them up into Nodes. It then creates vector embeddings of the text of every node, ready to be queried by an LLM.
LlamaIndex Chunking Strategy
When we use VectorStoreIndex.from_documents, the Documents are split into chunks and parsed into Node objects, which are lightweight abstractions over text strings that keep track of metadata and relationships.
A Node parser is responsible for taking in a list of documents, and chunking them into Node objects, such that each node is a specific chunk of the parent document. When a document is broken into nodes, all of its attributes are inherited by the children nodes (i.e. metadata, text and metadata templates, etc.).
Since our document is a Markdown, a MarkdownNodeParser will be used to parse the raw markdown text.
LlamaIndex offers various file-based node parsers designed to generate nodes according to the specific content type being processed, such as JSON, Markdown, and other formats.
You can read more about the LlamaIndex Node Parser here.
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import StorageContext
from llama_index.core.indices.vector_store.base import VectorStoreIndex
vector_store = QdrantVectorStore(client=qdrantClient, collection_name="stock_trade_data")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Create vector store index and store it in Qdrant DB
VectorStoreIndex.from_documents(documents, storage_context=storage_context)
Retrieval and Response Generation
Having successfully populated the vector database, the subsequent phase involves retrieving information from this store in response to user queries. Initially, embeddings are loaded into the VectorStoreIndex. Building upon this, a query engine is constructed. This engine serves as the intermediary, translating user inquiries into searchable formats and returning comprehensive responses derived from the vectorized data.
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import StorageContext
from llama_index.core.indices.vector_store.base import VectorStoreIndex
from llama_index.core.indices import load_index_from_storage
vector_store = QdrantVectorStore(client=qdrantClient, collection_name="stock_trade_data")
db_index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
# create a query engine for the index
query_engine = db_index.as_query_engine()
def get_response(query):
response = query_engine.query(query)
return response.response
Results
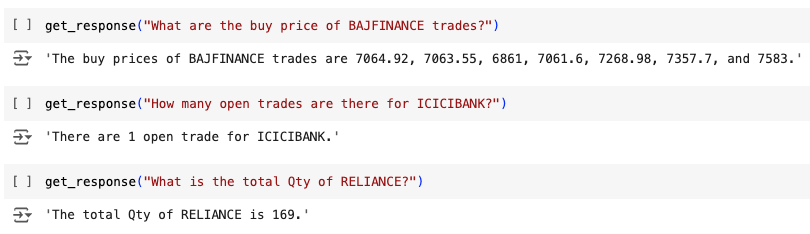
We will now assess the performance of our RAG pipeline by examining its responses to various stock-related queries. The following examples demonstrate the system's ability to accurately extract and provide information from the dataset.
Conclusion
This blog has outlined a methodology for constructing a Retrieval Augmented Generation (RAG) pipeline centered around Excel data. We've demonstrated the process of extracting information from Excel spreadsheets using LlamaParse, transforming it into a VectorStoreIndex format, and subsequently storing this index within a Qdrant database. The culmination of these steps is a functional RAG pipeline capable of providing informative responses to user inquiries based on the stored Excel data. If you have any questions regarding the topic, please don't hesitate to ask in the comment section. I will be more than happy to address them. You can find the source code of this project on this Google Colab page.
I frequently create content on building LLM applications, AI agents, vector databases, and other RAG-related topics. If you’re interested in similar articles, consider subscribing to my blog.
If you’re in the Generative AI space or LLM application domain, let’s connect on Linkedin! I’d love to stay connected and continue the conversation. Reach me at: linkedin.com/in/ritobrotoseth