


This blog post provides a technical guide to evaluating Retrieval Augmented Generation (RAG) pipelines using the Ragas framework.
What Is the Ragas Framework?
Ragas facilitates a comprehensive assessment of RAG pipeline performance by evaluating both the retrieval and generation components, independently and in conjunction. Four key metrics are employed to gauge RAG pipeline effectiveness:
Context Relevancy: This metric evaluates the signal-to-noise ratio in the retrieved contexts, that is, the relevancy of the retrieved context for the given question.
Context Recall: This metric measures the proportion of relevant contexts retrieved.
Faithfulness: This metric assesses the factual accuracy of the generated answer based on the provided context.
Answer Relevancy: This metric evaluates the relevance of the generated answer to the posed question.
We will read more about the metrics later in this blog. Ragas leverages LLMs to perform reference-free evaluations, mitigating biases and reducing costs. The framework supports the evaluation of RAG pipelines constructed with both LangChain and LlamaIndex. Our project focuses on evaluating a RAG pipeline built using LlamaIndex.
Project Details
Dependencies
The following is the list of dependencies used in this project:
pip install llama-index
pip install qdrant_client
pip install pypdf
pip install fastembed
pip install llama-index-embeddings-fastembed
pip install ragas
Building RAG Pipeline Using LlamaIndex
LlamaIndex is a data framework that can bridge the gap between custom data sources and LLMs like GPT-4. It allows users to ingest data from various sources, such as vector databases, files, etc. and then indexes this data into intermediate representations. The user can then query the data in natural language and interact with it using chat interfaces.
LlamaIndex works by first indexing the data into a vector index during the indexing stage, which creates a searchable knowledge base specific to the domain. During the querying stage, the system searches for relevant information based on the user's query and then provides this information to the LLM to generate an accurate response.
The first step in our RAG pipeline involves ingesting the FAQ data. This data will be loaded from a PDF document containing frequently asked questions (FAQs) on mutual funds. The PDF file can be accessed here.
# Load pdf file
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(input_files=["mutual_fund_faq.pdf"])
documents = reader.load_data()
Storing Data in Vector DB
The next step is to store the PDF data in Qdrant cloud DB. For that, we need a QdrantClient instance. The QdrantClient is a client library for interacting with the Qdrant DB. It provides a way to connect to a Qdrant instance and perform various operations such as creating collections, inserting vectors, searching for similar vectors, and filtering results. For initializing the QdrantClient we will need the QDRANT_URL and the QDRANT_API_KEY. The QDRANT_URL contains the Qdrant cloud cluster URL and the QDRANT_API_KEY contains the API key of the Qdrant DB cloud cluster.
Qdrant is an open-source vector database and vector search engine which provides a fast and scalable vector similarity search service. It is designed to handle high-dimensional vectors for performance and massive-scale AI applications. You can learn more about the Qdrant vector database here.
# Creating Qdrant client
from qdrant_client import QdrantClient
from google.colab import userdata
QDRANT_URL = userdata.get('QDRANT_URL')
QDRANT_API_KEY = userdata.get("QDRANT_API_KEY")
qdrantClient = QdrantClient(
url=QDRANT_URL,
prefer_grpc=True,
api_key=QDRANT_API_KEY)
For storing the data in vector DB, we first convert the data into numerical vectors or embeddings. In this project, I have used FastEmbedEmbedding to embed the data. I have defined the QdrantVectorStore instance to store the embeddings and docs in the Qdrant collection. I have created a new collection called mutual_fund_faq where I am storing all the pdf data. Finally, we are constructing VectorStoreIndex by converting the documents into embeddings and storing them in the Qdrant DB. The VectorStoreIndex will later be used for querying the data.
# Storing document into Qdrant Vector Store
from llama_index.core.indices.vector_store.base import VectorStoreIndex
from llama_index.core import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.embeddings.fastembed import FastEmbedEmbedding
from llama_index.core import Settings
Settings.embed_model = FastEmbedEmbedding(model_name="BAAI/bge-base-en-v1.5")
vector_store = QdrantVectorStore(client=qdrantClient, collection_name="mutual_fund_faq")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
Once the data is uploaded to the Qdrant collection, we can see the data in the collection dashboard.
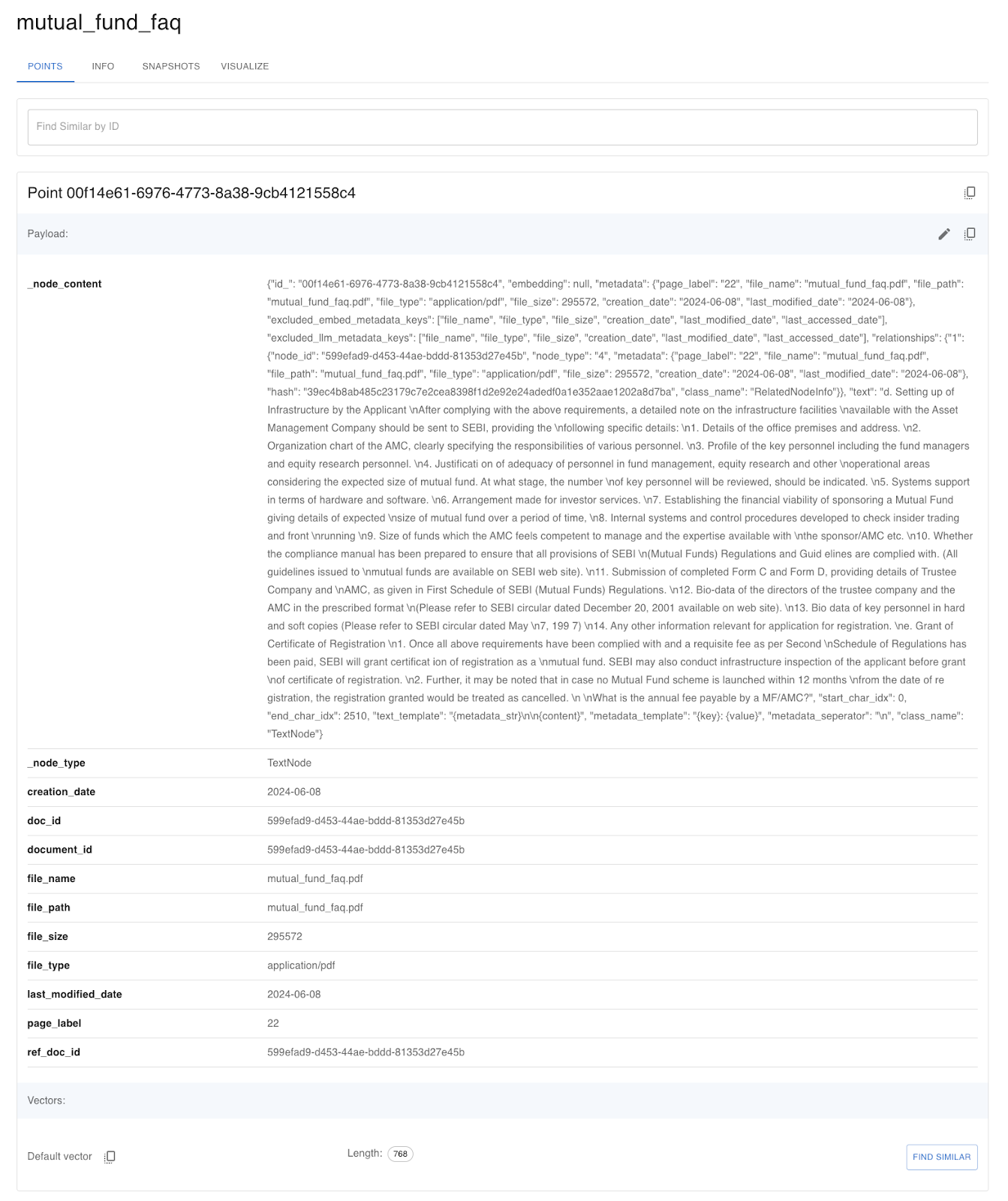
Query Retrieval Step
In the retrieval step, a series of things take place. The user first enters a query which is converted into embeddings. The system then retrieves the relevant documents from the vector store which are in close proximity to the query embeddings. This is done using techniques like nearest neighbor search or approximate nearest neighbor algorithms.
The retrieved documents are then used to augment the LLM's context and generate a response. What it means in simple terms is that the LLM extracts answers from the retrieved documents for the user's query and returns a refined answer to the user.
Below is the retrieval code. We have defined a query engine which uses the VectorStoreIndex for retrieving the documents from the vector store, and then using the OpenAI LLM model to generate the answer.
# Querying Qdrant Vector store
import os
from llama_index.llms.openai import OpenAI
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
llm = OpenAI(model="gpt-3.5-turbo-0125")
query_engine = index.as_query_engine(llm = llm)
response = query_engine.query("How mutual fund performance is calculated?")
print(response.response)
Below is the answer we received:
Mutual fund performance is typically calculated by comparing the
fund's returns to a benchmark index or to other funds in the same
category. Investors can assess the performance of mutual funds by
looking at their past track record, comparing them with similar
investment objectives, and analyzing factors like NAV movements,
market value, and professional management efficiency. It is important
to note that past performance is not a guarantee of future results,
but it is still a significant factor in evaluating mutual fund
performance.
Evaluating the RAG Pipeline
Having constructed our RAG pipeline, we will employ the Ragas framework to assess its performance. The initial step involves generating synthetic data, utilizing the same PDF document for this purpose. To begin, the PDF file is loaded using the LangChain document loader.
from langchain_community.document_loaders import PyPDFLoader
file_path = ("mutual_fund_faq.pdf")
loader = PyPDFLoader(file_path)
documents = loader.load_and_split()
Next, we will be using the TestsetGenerator module to build the test dataset. The generate_with_langchain_docs method is responsible for generating the dataset. The test_size attribute determines the size of the dataset whereas the distributions attribute determines how to distribute the dataset based on the evaluation type. The generated test dataset contains the following columns:
question: Contains the questions for the RAG Pipeline Assessment.
context: The context provided to the LLM for question answering.
ground_truth: The ground truth answer to the question.
evaluation_type: The different evaluation types of the question, like simple, reasoning, or multi-context.
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
critic_llm = ChatOpenAI(model="gpt-4o")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# generate testset
testset = generator.generate_with_langchain_docs(documents, test_size=10, distributions={simple: 0.5, reasoning: 0.25, multi_context: 0.25})
To view the test data frame, run the below command:
test_df = testset.to_pandas()
test_df

Below are all 10 question-answer sets along with the evolution type.
question | ground_truth | evolution_type |
What information is required for an applicant to apply for SEBI registration for a mutual fund? | An applicant should apply for registration in form A prescribed under Schedule I of SEBI (Mutual Funds) Regulations 1996. The applicant should also submit a complete list of names of associate organizations/group companies/subsidiaries registered with SEBI, details of any violations of securities related regulations and actions taken against them, details of monetary penalties imposed, details of suspensions and cancellations of registration certificates for the last 10 years. | simple |
How is the Net Asset Value (NAV) of a mutual fund scheme disclosed to investors? | The performance of a scheme is reflected in its NAV which is disclosed on daily basis. The NAVs of mutual funds are required to be published on the web sites of mutual funds. All mutual funds are also required to put their NAVs on the web site of Association of Mutual Funds in India (AMFI) www.amfiindia.com and thus the investors can access NAVs of all mutual funds at one place. | simple |
How can an investor determine the market value of investments in different mutual fund schemes? | Investors can determine the market value of investments in different mutual fund schemes by multiplying the number of units with the Net Asset Value (NAV) of each scheme. The NAV represents the per-unit value of the scheme, and multiplying it by the number of units held gives the total market value of the investment in that scheme. | simple |
How long does a mutual fund take to dispatch dividend warrants to unit holders after the declaration of the dividend? | A mutual fund is required to dispatch to the unitholders the dividend warrants within 30 days of the declaration of the dividend. | simple |
What steps are required to be undertaken within 12 months if found eligible after SEBI examines the application for registration? | If found eligible after SEBI examines the application for registration, the following steps need to be undertaken within a period of 12 months from the date of communication: Incorporation of the Asset Management Company and the Trustee Company/Board of trustees, submission of Auditor's certificate, and filing of executed copies of Trust Deed and Investment Management Agreement. | simple |
How do scheme objectives and risk levels affect investor wealth creation in the short, medium, or long term? | The nature of the scheme, investment objective, and risk level (depicted by a riskometer) all play a crucial role in determining investor wealth creation in the short, medium, or long term. The scheme's nature dictates whether it aims to create wealth or provide regular income within a specific time horizon. The investment objective, typically summarized in a single line, outlines the goal of the investment and the type of product (Equity/Debt) in which the investor is investing. The risk level, indicated by the riskometer, helps investors understand the level of risk associated with the investment, ranging from low to high. Investors should consider these factors and consult their financial advisers to assess the suitability of the product for their investment goals and risk tolerance. | reasoning |
How much does an MF/AMC pay SEBI annually for registration? | nan | reasoning |
What are SEBI regulations for mutual fund schemes in India? | SEBI has mandated that no entry load can be charged for any mutual fund scheme in India. Mutual funds cannot increase the exit load beyond the level mentioned in the offer document. Any change in the load will be applicable only to prospective investments and not to the original investments. | multi_context |
How do close-ended and open-ended mutual fund schemes differ in terms of maturity and liquidity? | Close-ended mutual fund schemes have a stipulated maturity period, typically 3-5 years, and are open for subscription only during a specified period at the time of launch. Investors can buy or sell units on stock exchanges where the units are listed. Some close-ended funds offer an exit route through periodic repurchase at NAV related prices. On the other hand, open-ended mutual fund schemes do not have a fixed maturity period and are available for subscription and repurchase on a continuous basis. Investors can conveniently buy and sell units at NAV per unit, which is declared daily, providing liquidity. | multi_context |
How can investors track a mutual fund's performance and stay updated on changes in attributes and asset allocation? | Investors can track a mutual fund's performance through its Net Asset Value (NAV), which is disclosed daily on the mutual fund websites and the Association of Mutual Funds in India (AMFI) website. Mutual funds are required to have a dashboard on their websites providing performance and key disclosures for each scheme. Additionally, mutual funds publish half-yearly results that include returns over various periods, expenses as a percentage of total assets, and other relevant information. New investors are informed about material changes through addendums to the offer document until the Scheme Information Document (SID) is revised and reprinted. Annual reports or abridged annual reports are sent to unit holders at the end of the year. | multi_context |
If leveraging the synthetic QA dataset is not preferred, you can opt for manual curation of a question-answer (QA) dataset specific to your document for RAG pipeline evaluation.
Now we are all set to evaluate the RAG pipeline. First, we will import the evaluation metrics which are: answer_relevancy, faithfulness, context_recall, and context_precision. Apart from these 4 metrics, we have other metrics too like answer_correctness, answer_similarity, ContextRelevancy, etc. Next, we will extract the list of questions and answers from the synthetic test dataset. We will iterate through all the questions and pass them to our RAG application to get answers to these questions. We will be preparing 2 more lists where we will store the answers from our RAG and the list of contexts that were used to answer the question.
Finally, we will prepare an evaluation dataset dictionary where we aggregate all 4 attributes: question, answer, contexts, and ground_truth. We will then call the evaluate function on the evaluation dataset dictionary and the metrics for evaluating the RAG pipeline.
from datasets import Dataset
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
from ragas import evaluate
questions = test_df['question'].tolist()
ground_truths = test_df['ground_truth'].tolist()
answers = []
contexts = []
for question in questions:
answer = query_engine.query(question)
answers.append(answer.response)
context_list = [source_node.text for source_node in answer.source_nodes]
contexts.append(context_list)
data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truths
}
evaluation_dataset = Dataset.from_dict(data)
evaluation_result = evaluate(
dataset = evaluation_dataset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
evaluation_df = evaluation_result.to_pandas()
evaluation_df[['question', 'answer', 'ground_truth', 'context_precision', 'faithfulness', 'answer_relevancy', 'context_recall']]
The output is the evaluation report which scores all 4 metrics.

The 4 metrics on which the RAG pipeline is evaluated are:
Context Precision: Context Precision is a metric that evaluates whether all of the ground-truth relevant items present in the contexts are ranked high or not. Ideally, all the relevant chunks must appear in the top ranks. This metric is computed using the question, ground_truth and the contexts, with values ranging between 0 and 1, where higher scores indicate better precision.
Faithfulness: This measures the factual consistency of the generated answers against the given context. It is calculated from the answer and the retrieved context. The answer is scaled in the (0,1) range. The higher, the better. The generated answer is regarded as faithful if all the claims made in the answer can be inferred from the given context. To calculate this, a set of claims from the generated answer is first identified. Then each one of these claims is cross-checked with the given context to determine if it can be inferred from that context or not.
Answer Relevance: Answer relevancy focuses on assessing how pertinent the generated answer is to the given prompt. A lower score is assigned to answers that are incomplete or contain redundant information while higher scores indicate better relevancy. This metric is computed using the question, the context, and the answer.
Context Recall: Context recall measures the extent to which the retrieved context aligns with the annotated answer, treated as the ground truth. It is computed based on the ground truth and the retrieved context, and the values range between 0 and 1, with higher values indicating better performance.
To Summarize
This blog aimed to elucidate the utilization of the Ragas framework for RAG pipeline evaluation and performance assessment. We explored the construction of a rudimentary RAG pipeline leveraging LlamaIndex. Subsequently, we delved into the application of Ragas for synthetic dataset generation to facilitate RAG pipeline evaluation.
If you have any questions regarding the subject, please don't hesitate to ask in the comments section. I will be more than happy to address them.
I regularly create similar content on LangChain, LlamaIndex, Vector databases, and other RAG topics. If you'd like to read more articles like this, consider subscribing to my blog.
If you're in the Generative AI space or LLM application domain, let's connect on Linkedin! I'd love to stay connected and continue the conversation. Reach me at: linkedin.com/in/ritobrotoseth