Guide to Building a QA RAG AI for Enterprises Using Spring AI, Qdrant, and Gemma-7B

In this tutorial, we will build a Question Answering RAG application in Spring AI. Spring AI simplifies building AI-powered applications. It leverages the familiar concepts of portability and modularity from the Spring ecosystem, making it easy to integrate different AI components. Spring AI also encourages using plain Java objects (POJOs) as the foundation of your AI application, promoting a clean and familiar development experience. Currently, Spring AI supports a lot of LLM models like OpenAI. MistralAI, Google VertexAI, and models supported by Ollama text generation. We will be using an offline AI model gemma:7b running locally with Ollama.
For storing and retrieving high-dimensional vector data for our RAG application, we will be using Qdrant DB. Finally, we will be querying our Spring AI RAG application endpoints with Postman to generate answers to the user’s questions. In our RAG application, we will use Amazon product reviews as an external data source to answer any user’s query related to the product.
Prerequisite for Spring AI Project
The Spring CLI is the prerequisite for setting up a Spring AI project. On macOS, we can leverage Homebrew, a popular package manager, for installation. Execute the following commands sequentially:
$ brew tap spring-cli-projects/spring-cli
$ brew install spring-cli
For detailed instructions on Spring CLI installation across various operating systems, consult the official installation guide.
Creating Spring AI Application
Use the below command to create the Spring AI application using the Spring CLI tool:
$ spring boot new --from ai --name spring-ai-rag-app
spring-ai-rag-app is the project name. Check out more about the Spring AI application framework here.

While the provided command generates a basic ChatGPT interaction application, our project requires the gemma:7b model running locally with Ollama. To achieve this, we'll need to modify the application configuration.
Spring AI Project Setup
First, let's open the project in a Java IDE. Next, we will update the pom.xml and application.properties files per our required configs.
Updating pom.xml
By default, the newly created project comes with OpenAI dependency.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
We need to replace the OpenAI dependency with the Ollama dependency.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
Next, we need to add the Qdrant vector store dependency.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-qdrant</artifactId>
</dependency>
Other than these, we will be adding logback for logging and lombok to minimize or remove boilerplate Java code.
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
Updating application.properties file
The next step involves creating a dedicated resource directory within the project structure. This directory will house the application.properties file, which stores the configuration settings for the Qdrant database.
spring.ai.vectorstore.qdrant.host=<Qdrant_Cluster_URL>
spring.ai.vectorstore.qdrant.port=6334
spring.ai.vectorstore.qdrant.api-key=<Qdrant_API_Key>
spring.ai.vectorstore.qdrant.collection-name=amazon_product_review
spring.ai.vectorstore.qdrant.use-tls=true
You can read more about the Qdrant DB configurations here.
Updating Package and File names
This part is optional. I want to keep the package name short and relevant to this project. That's why I have updated the package name as per the project. I have changed the package name from org.springframework.ai.openai.samples to ollama.rag. Inside the ollama.rag package, we have a sub-package named simple, which we will rename to questionanswering. Since we are building a QA RAG application, we will rename our existing controller SimpleAiController to QaController.
Adding Dataset for Retrieval
For our question-answering retriever data, we will be using the Amazon product review dataset. The CSV file for this dataset can be downloaded from the link I have provided. I have downloaded the file and renamed it to amazon_product_reviews.csv; post that I have moved the file inside the project resource directory. Below is the screenshot of the contents of the file where I have highlighted the relevant columns.

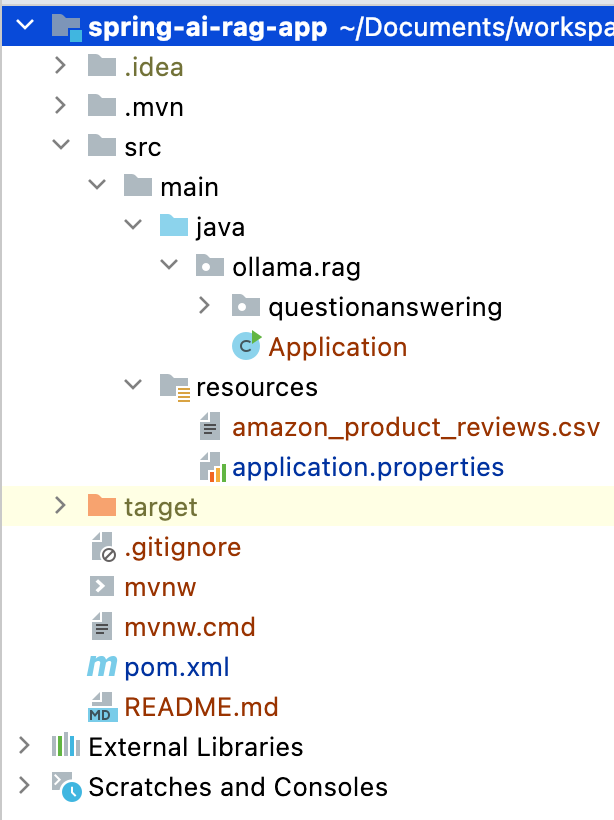
Post performing all the above-mentioned changes, below is the final structure of the project.
Code Walkthrough
The backend has 2 components: one is the data ingestion part where we store information in the Qdrant Vector DB; the second part is Retrieval, where we retrieve relevant information from the Vector DB.
Data Ingestion Flow
We have created a separate controller for data ingestion called DataIngestionController. We have exposed 2 endpoints:
/data/range: For inserting a range of Amazon product reviews from theamazon_product_reviews.csvfile./data/firstn: For inserting the first N number of product reviews from theamazon_product_reviews.csvfile.
The user can select the appropriate endpoint based on their requirement.
import java.util.Map;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
@AllArgsConstructor
@Component
@Slf4j
public class DataIngestionController {
private final DataIngestionService dataIngestionService;
@PostMapping("/data/range")
public Map<String, String> insertDocsInRange(@RequestBody DataIngestionParamsDto dataIngestionParamsDto) {
dataIngestionService.insertDocsInRange(dataIngestionParamsDto.getOffset(), dataIngestionParamsDto.getLimit());
return Map.of("result", "success");
}
@PostMapping("/data/firstn")
public Map<String, String> insertFirstNDocs(@RequestBody DataIngestionParamsDto dataIngestionParamsDto) {
dataIngestionService.insertFirstNDocs(dataIngestionParamsDto.getLimit());
return Map.of("result", "success");
}
}
We have injected DataIngestionService in our controller class, where we have defined the methods for DB insertion. The DataIngestionService has 2 methods: insertDocsInRange for inserting the range of rows and insertFirstNDocs for inserting the first N number of rows.
import com.google.common.collect.Lists;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.csv.CSVFormat;
import org.apache.commons.csv.CSVParser;
import org.apache.commons.csv.CSVRecord;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.Resource;
import org.springframework.core.io.ResourceLoader;
import org.springframework.stereotype.Component;
@Component
@AllArgsConstructor
@Slf4j
public class DataIngestionService {
private final VectorStore vectorStore;
private final ResourceLoader resourceLoader;
public void insertDocsInRange(long offset, long limit) {
var reviews = processCSVFile("amazon_product_reviews.csv");
var documents = reviews.stream()
.skip(offset) // Skip elements based on offset
.limit(limit) // Limit the number of elements to retrieve
.map(review -> new Document(review.productReview(), Map.of("productName", review.productName())))
.toList();
// Add the documents to Qdrant
vectorStore.add(documents);
log.info("Data updated successfully");
}
public void insertFirstNDocs(long limitSize) {
var reviews = processCSVFile("amazon_product_reviews.csv");
var documents = reviews.stream()
.limit(limitSize)
.map(review -> new Document(review.productReview(), Map.of("productName", review.productName())))
.toList();
// Add the documents to Qdrant
vectorStore.add(documents);
log.info("Data updated successfully");
}
public record ProductReviewData(String productName, String productReview) { }
/**
* Read the data from the CSV file
*/
public List<ProductReviewData> processCSVFile(String filename) {
try {
Resource resource = resourceLoader.getResource("classpath:" + filename);
BufferedReader reader = new BufferedReader(new InputStreamReader(resource.getInputStream()));
CSVParser csvParser = new CSVParser(reader, CSVFormat.DEFAULT.withHeader());
var amazonReview = new ArrayList<ProductReviewData>();
var productIntro = "This section contains the user review of the product: '";
var reviewIntro = "Following is the user review of the product: ";
for (CSVRecord record : csvParser) {
String name = record.get("name");
String reviewTitle = record.get("reviews.title");
String reviewText = record.get("reviews.text");
// Concatenate the values
String concatenatedString = productIntro + name + "'. " + reviewIntro + reviewTitle + " - " + reviewText;
amazonReview.add(new ProductReviewData(name, concatenatedString));
}
csvParser.close();
reader.close();
return amazonReview;
} catch (IOException e) {
e.printStackTrace();
return Lists.newArrayList();
}
}
}
In our DataIngestionService class we have injected VectorStore, which is an interface that implements the QdrantVectorStore class. The QdrantVectorStore class is responsible for inserting the list of documents into the DB collection. The configs of Qdrant VectorStore are pulled from the application.properties file, which we have discussed in the previous section of this blog.
The private method processCSVFile returns a list of ProductReviewData records; each record contains the product name and the product review in string format. While inserting the product review in Qdrant DB, we are also adding the product name in the metadata. Below is the screenshot of the record from the Qdrant collection.
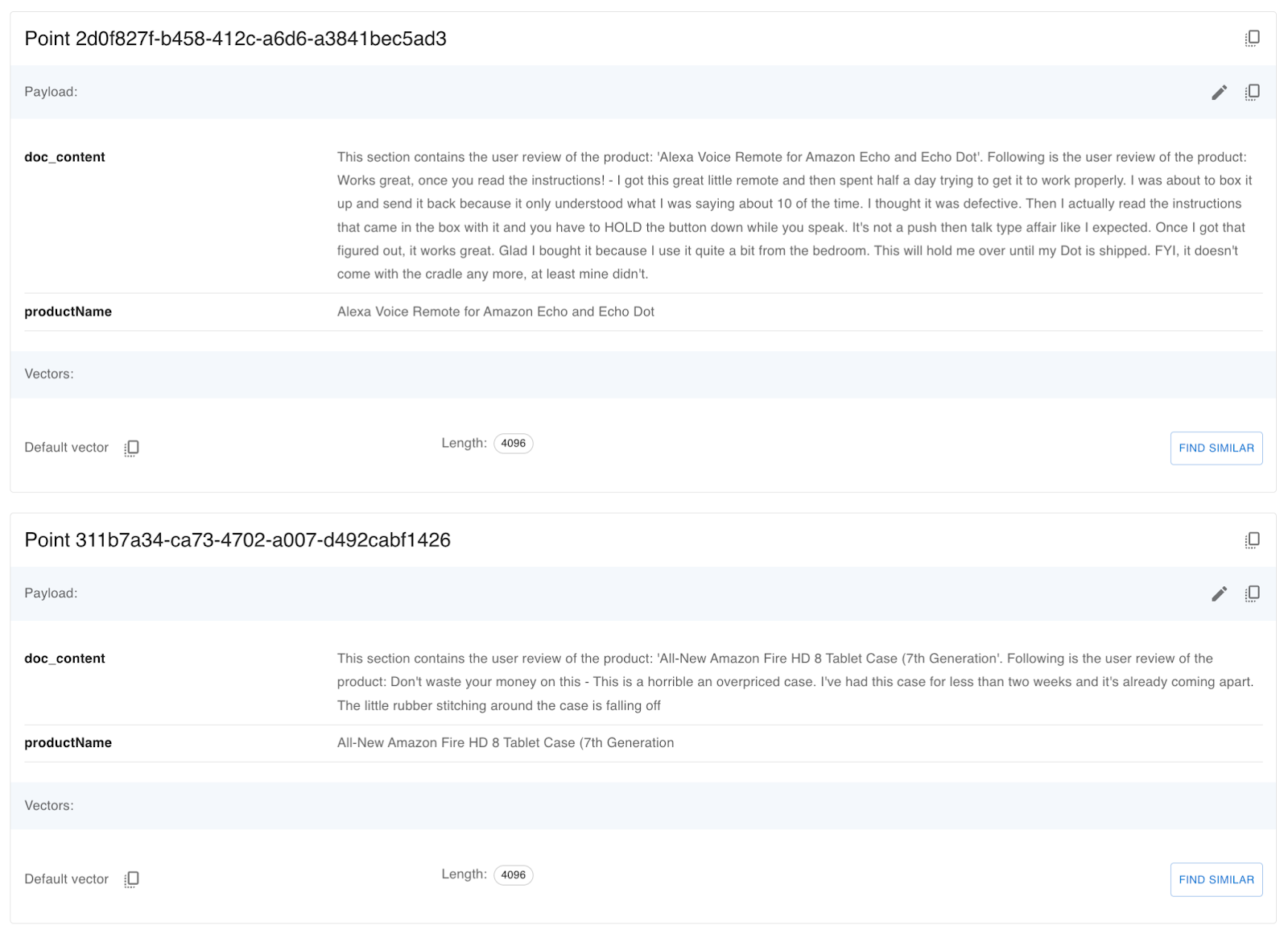
In our DataIngestionController we have used the RequestBody of type DataIngestionParamsDto; below is the class definition of the DTO:
import lombok.Data;
@Data
public class DataIngestionParamsDto {
private long offset;
private long limit;
}
Retrieval Flow
For the retrieval part, QaController is used and it contains only one endpoint /qa/response. This endpoint accepts questions from the user and returns answers produced by the LLM based on the product review.
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import ollama.rag.questionanswering.dto.ChatRequestDto;
import ollama.rag.questionanswering.dto.ChatResponseDto;
import org.springframework.stereotype.Component;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
@AllArgsConstructor
@Component
@Slf4j
public class QaController {
private final QaService qaService;
@PostMapping("/qa/response")
public ChatResponseDto completion(@RequestBody ChatRequestDto chatRequestDto) {
return qaService.getAnswer(chatRequestDto.getUserMsg());
}
}
We have injected a QaService object in our controller class, where the logic exists to deliver tailored and relevant information to users based on their queries and the retrieved context from the vector store.
import static ollama.rag.questionanswering.Prompts.FIND_PRODUCT_PROMPT;
import static ollama.rag.questionanswering.Prompts.ANSWER_QUESTION_FROM_REVIEW_PROMPT;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import ollama.rag.questionanswering.dto.ChatResponseDto;
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.ollama.api.OllamaOptions;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
@AllArgsConstructor
@Component
@Slf4j
public class QaService {
private final VectorStore vectorStore;
private final ChatClient chatClient;
public ChatResponseDto getAnswer(final String userQuestion) {
var chatOptions = OllamaOptions.create()
.withModel("gemma:7b")
.withTemperature((float) 0.1);
var foundProduct = findProductName(userQuestion, chatOptions);
if (foundProduct.isEmpty()) {
return defaultFailedResponse();
}
List<Document> fetchedVectorStoreDocs = vectorStore.similaritySearch(SearchRequest
.query(userQuestion)
.withTopK(5)
.withFilterExpression("productName == '" + foundProduct.get() + "'")
);
var relevantStringDocs = getRelevantStringDocs(fetchedVectorStoreDocs, userQuestion, chatOptions);
if (CollectionUtils.isEmpty(relevantStringDocs)) {
return defaultFailedResponse();
}
String stuffedReviews = "";
for(var stringDoc: relevantStringDocs) {
stuffedReviews += stringDoc;
}
var finalLlmResponse = extractAnswerFromContext(userQuestion, stuffedReviews, chatOptions);
return ChatResponseDto.builder()
.aiResponse(finalLlmResponse.getResult().getOutput().getContent())
.refDocs(relevantStringDocs)
.build();
}
private ChatResponseDto defaultFailedResponse() {
return ChatResponseDto.builder()
.aiResponse("I don't have answer of this question")
.build();
}
private List<String> getProductCatalog() {
return List.of(
"Alexa Voice Remote for Amazon Echo and Echo Dot",
"Alexa Voice Remote for Amazon Fire TV and Fire TV Stick",
"All-New Amazon Fire 7 Tablet Case (7th Generation",
"All-New Amazon Fire HD 8 Tablet Case (7th Generation",
"All-New Amazon Fire TV Game Controller",
"All-New Amazon Kid-Proof Case for Amazon Fire 7 Tablet (7th Generation",
"All-New Amazon Kid-Proof Case for Amazon Fire HD 8 Tablet (7th Generation",
"All-New Fire 7 Kids Edition Tablet",
"All-New Fire 7 Tablet with Alexa",
"All-New Fire HD 8 Kids Edition Tablet",
"All-New Fire HD 8 Tablet with Alexa",
"Amazon 5W USB Official OEM Charger and Power Adapter for Fire Tablets and Kindle eReaders",
"Amazon Echo - Black",
"Amazon Echo Dot Case (fits Echo Dot 2nd Generation only) - Charcoal Fabric"
);
}
private Optional<String> findProductName(final String userQuestion, final OllamaOptions ollamaOptions) {
var productList = getProductCatalog();
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(FIND_PRODUCT_PROMPT);
var productListString = "";
for (var product: productList) {
productListString += product + "\n";
}
Message systemMessage = systemPromptTemplate.createMessage(Map.of("PRODUCT_LIST", productListString));
Message userMessage = new UserMessage(userQuestion);
Prompt prompt = new Prompt(List.of( systemMessage, userMessage), ollamaOptions);
var productNameLlmResponse = chatClient.call(prompt);
var productNameResponse = productNameLlmResponse.getResult().getOutput().getContent();
return getProductCatalog().stream().
filter(product -> productNameResponse.contains(product))
.findFirst();
}
private List<String> getRelevantStringDocs(final List<Document> fetchedVectorStoreDocs, final String userQuestion, final OllamaOptions ollamaOptions) {
var relevantDocs = new ArrayList<String>();
for(var result: fetchedVectorStoreDocs) {
var llmResponseLevel1 = extractAnswerFromContext(userQuestion, result.getContent(), ollamaOptions);
if (llmResponseLevel1.getResult().getOutput().getContent().contains("I don't have answer of this question")
|| llmResponseLevel1.getResult().getOutput().getContent().contains("I cannot answer")) {
continue;
}
relevantDocs.add(result.getContent());
}
return relevantDocs;
}
private ChatResponse extractAnswerFromContext(final String userQuestion, final String docContent, final OllamaOptions ollamaOptions) {
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(
ANSWER_QUESTION_FROM_REVIEW_PROMPT);
Message systemMessage = systemPromptTemplate.createMessage(Map.of("CONTEXT", docContent));
Message userMessage = new UserMessage(userQuestion);
Prompt prompt = new Prompt(List.of( systemMessage, userMessage), ollamaOptions);
return chatClient.call(prompt);
}
}
In the QaService class, we have injected 2 objects VectorStore and ChatClient. VectorStore, as discussed above, is the implementation of the QdrantVectorStore class, which is responsible for retrieving the list of relevant documents from the DB.
Spring AI provides Spring Boot auto-configuration for the Ollama Chat Client, which gets enabled by default on adding the Ollama dependency in the projects pom.xml file. We have already discussed the same in the updating pom.xml section of this blog.
Based on the user’s question, we are first figuring out the name of the product. This is done by the findProductName method. This method calls the LLM with the user question and the list of products in the inventory; then it instructs the model to find the product name from the list that matches most with the user’s question. For finding the product name, we are using a prompt stored in the FIND_PRODUCT_PROMPT variable in the Prompts interface.
Once the matched product is found, we make a product filter search to Qdrant DB along with the user’s question. The fetched vector documents are passed to the LLM one by one along with the user’s question to extract answers from the review. The method getRelevantStringDocs is responsible for analyzing each of these vector documents. It checks if the LLM is able to find the answer to the question in the document or not. If the LLM response contains the string I don't have answer of this question or I cannot answer, then that means the document does not contain the answer. If it does contain the answer, then we add the content of the document to the relevantDocs array. Finally, all the documents in the relevantDocs array are merged together and passed to the LLM to get the complete answer to the user’s question. For finding the relevant documents and for generating the final response to the user’s question, we are using the same prompt which is stored in the ANSWER_QUESTION_FROM_REVIEW_PROMPT variable in the Prompts interface.
The OllamaOptions objects that we have defined at the beginning of the getAnswer method provide the model configurations, such as the model to use, the temperature, etc. Here we are using the gemma:7b LLM model with the temperature set to 0.1. We then pass both the chatOptions and the list of messages as an argument to the Prompt constructor. The Prompt class acts as a container for an organized series of Message objects, with each one forming a segment of the overall prompt. Every Message embodies a unique role within the prompt, differing in content and intent. Finally, the ChatClient.call method is called, which internally calls the LLM with the prompt for generating the response.
As mentioned earlier in the Prompts interface, we have defined the prompts ANSWER_QUESTION_FROM_REVIEW_PROMPT and FIND_PRODUCT_PROMPT. These prompts are used in the question-answering process by QaService.
public interface Prompts {
String ANSWER_QUESTION_FROM_REVIEW_PROMPT =
"""
You are an online product review analyzer. You are given a set of paragraphs containing the product REVIEW. Use the product REVIEW to answer user's question.
If the answer is not present in the REVIEW reply: `I don't have answer of this question`
You are instructed to respond in a concise and informative manner, avoiding redundant or tangential details. Focus on providing the most relevant answer to the query.
----------------------------------
Below is the REVIEW:
{CONTEXT}
----------------------------------
Follow the following format to answer the question:
Answer: <your answer>
""";
String FIND_PRODUCT_PROMPT = """
You are given a list of products, based on user's question find the best match from the product list:
----------------------------------
Below is the product list:
{PRODUCT_LIST}
----------------------------------
You are instructed to return only the product name from the list in response:
----------------------------------
Below is the user's question:
""";
}
In our QaController we have used the RequestBody of type ChatRequestDto, and the return type is ChatResponseDto. Below is the class definition of both the DTOs:
ChatRequestDto class:
import lombok.Data;
@Data
public class ChatRequestDto {
private String userMsg;
}
ChatResponseDto class
import java.util.List;
import lombok.Builder;
import lombok.Data;
@Builder
@Data
public class ChatResponseDto {
private String aiResponse;
private List<String> refDocs;
}
The aiResponse variable contains the answer to the user's question and the refDocs list contains the list of documents (product reviews) referred by the LLM to answer the user’s question.
Backend In Action
Data Ingestion in Action
Now we are all set to try out the Spring AI application. To run the App we need to right-click on the Application file and then select Run 'pplication.main()'.
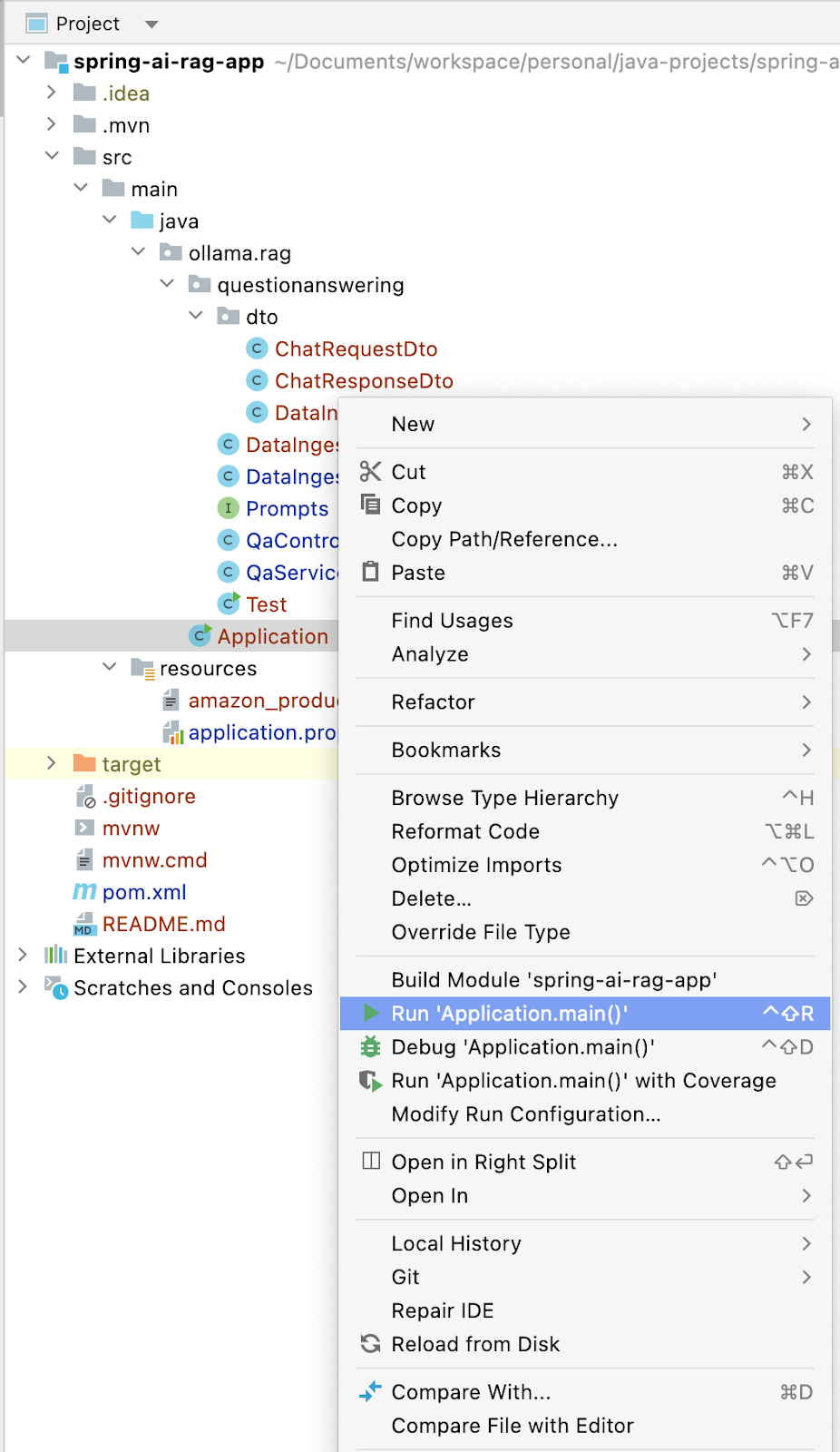
Let's first try to insert some documents into the Qdrant DB with the help of /data/firstn endpoint.
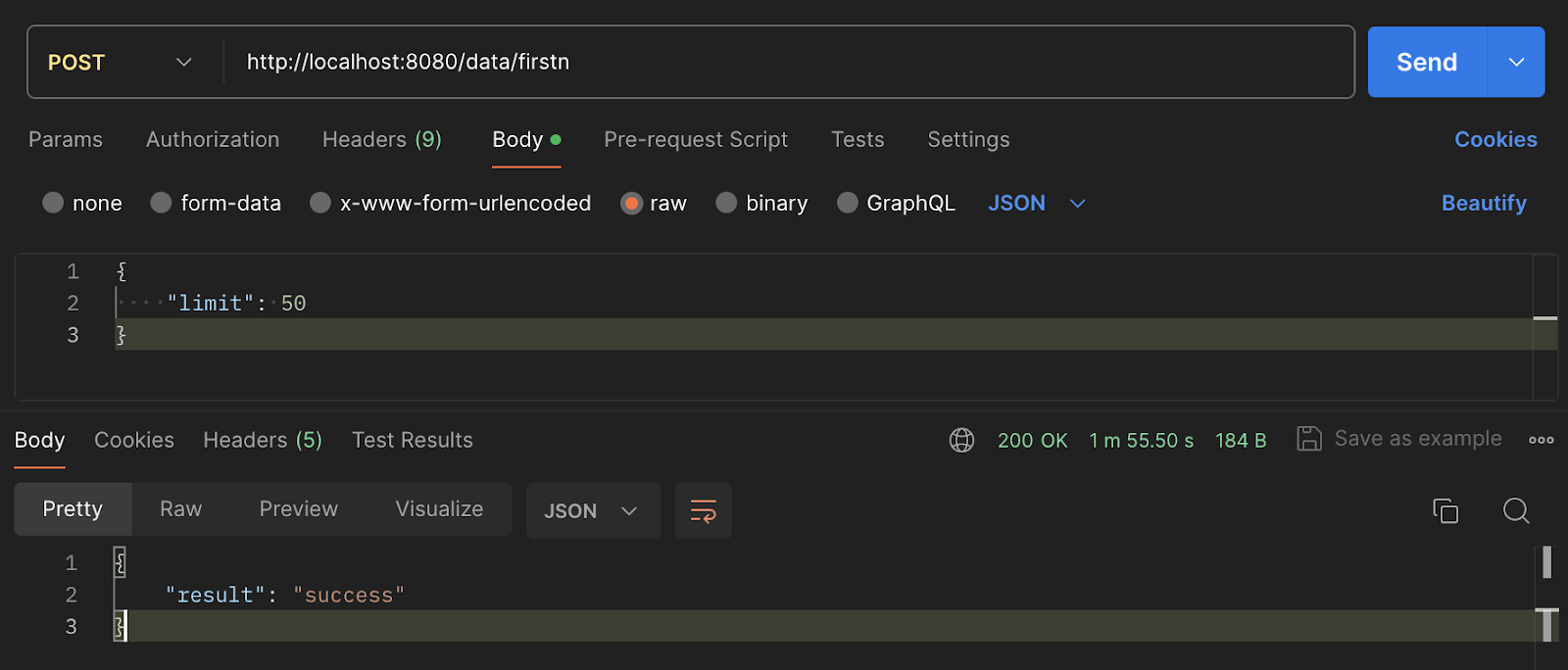
We successfully inserted the first 50 records into the Qdrant DB.
Now let's try out the second endpoint /data/range for inserting documents within a range. Here we have successfully inserted a batch of records – from 101 to the next 100 records.

Retrieval in Action
Now that we have successfully inserted external documents into the vector store, let's try the retrieval part. The userMsg contains the query requested by the user. The response from the RAG application can be found below, which contains the answer to the user query.
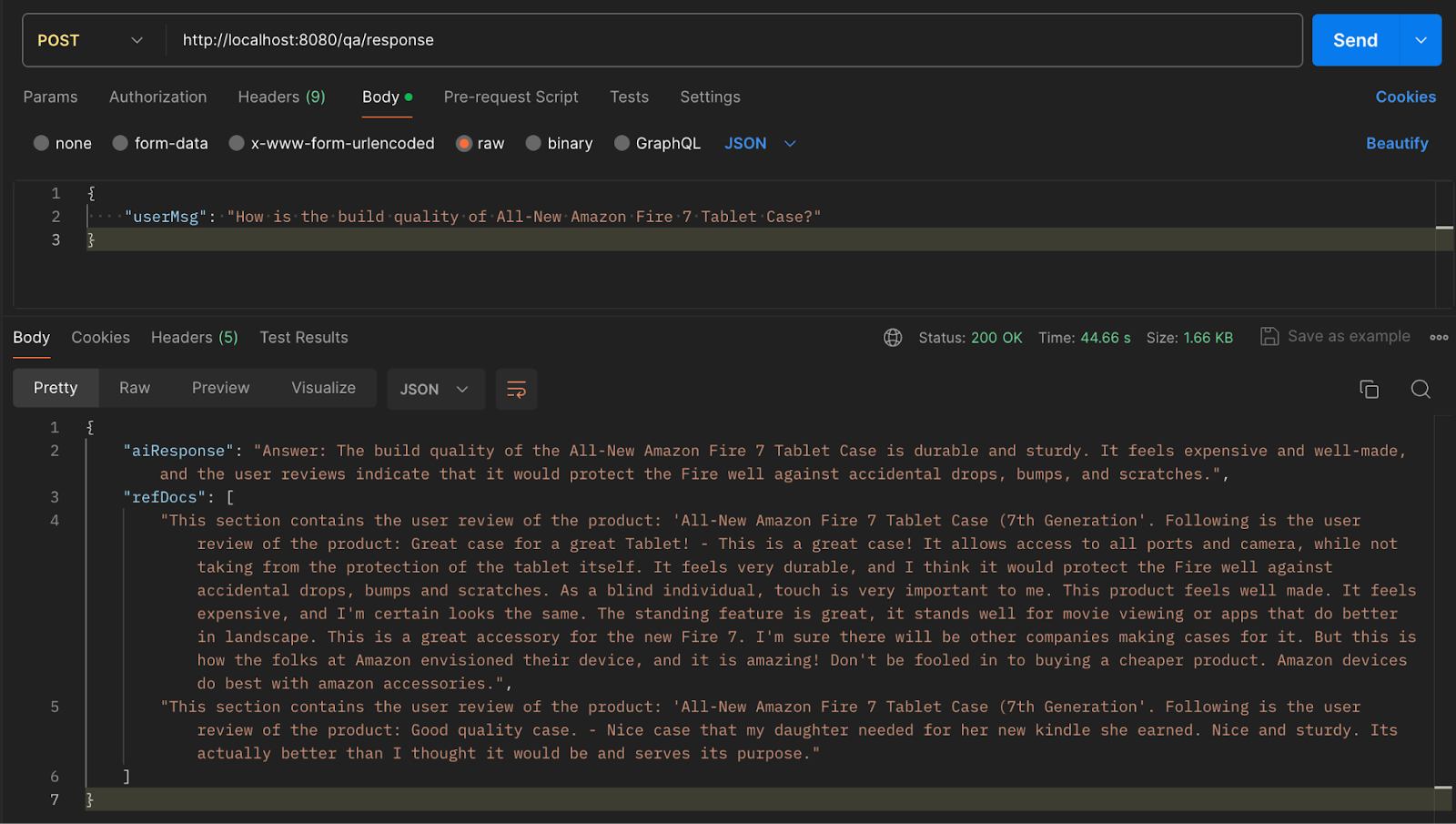
Along with the answer, we are also returning a list of reference docs that contains the original reviews used by the LLM to answer the user’s question.
Let's try another query.
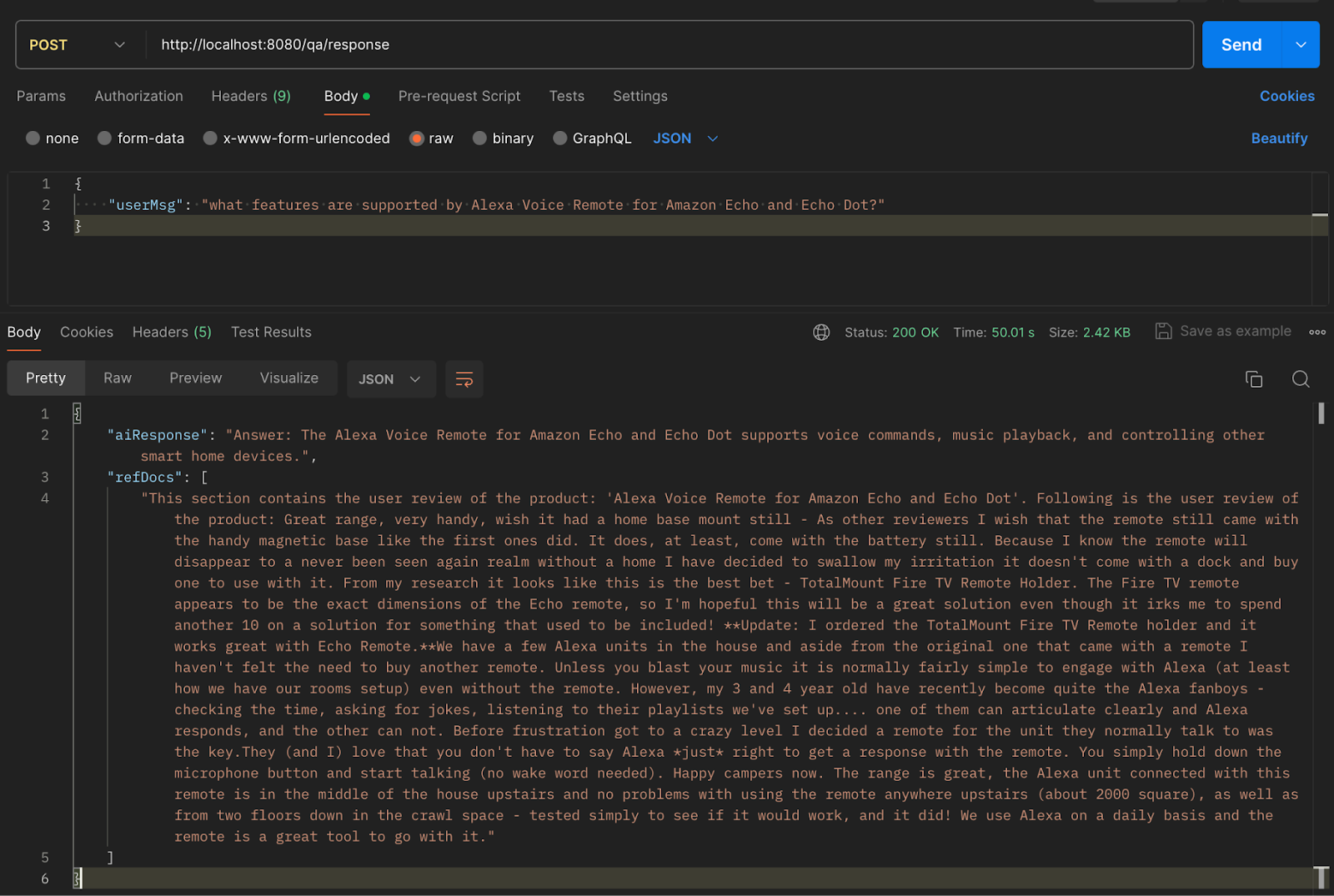
We have come to the end of our experiment.
This blog has equipped you with the knowledge to build a QA RAG App for enterprises using Spring AI, Qdrant, and Gemma-7B. We've covered:
Setting up a Spring AI application.
Configuring project dependencies and properties for Qdrant.
Building a data ingestion flow to populate Qdrant with Amazon product reviews.
Constructing a RAG application that answers user questions based on the reviews.
With this foundation, you can now leverage Spring AI's capabilities to create intelligent question-answering systems tailored to your specific needs.
If you have any questions regarding the topic, please don't hesitate to ask in the comment section. I will be more than happy to address them.
I regularly create similar content on building AI applications, LLMs, and related AI topics. If you'd like to read more articles like this, consider subscribing to my blog.
If you're in the LLM domain, let's connect on Linkedin! I'd love to stay connected and continue the conversation. Reach me at: linkedin.com/in/ritobrotoseth




