


Table of contents
In this blog, we will create a multi-user RAG chatbot designed for students. This chatbot is available for students from various departments to inquire about topics related to their specific field. For instance, a science student can ask science-related questions and a history student can inquire about historical topics. However, if a student asks questions outside their department, they won't receive answers to those questions.
I have used Streamlit for the user interface, the Langchain framework, and Qdrant Vector Database for building this multi-user RAG chatbot. To limit data access to specific departments, I have set up multi-tenancy in Qdrant DB. This means data is separated between users, specifically by department. For instance, a user from a particular department can only access data from that department. To achieve this, I added the group_id field to each vector; this field contains the department name which helps partition the data based on the department.
We have installed the following Python dependencies for building this App:
pip install langchain
pip install qdrant-client
pip install langchain_openai
pip install langchain_community
pip install streamlit
Inserting Data in Vector Store
In this section, we will learn to tag our documents with the department name and write the documents in Qdrant DB. The first step is chunking the data and for that, I have used the Langchain CharacterTextSplitter function.
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
CHUNK_SIZE = 1500
CHUNK_OVERLAP = 300
def chunk_data(file_name):
loader = TextLoader(file_name)
documents = loader.load()
text_splitter = CharacterTextSplitter(
separator="\n\n", chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
return text_splitter.split_documents(documents)
After chunking, the documents are tagged with the department name.
def tag_documents(docs, department):
taggedDocs = []
for doc in docs:
doc.metadata = {"group_id": department}
taggedDocs.append(doc)
return taggedDocs
Post tagging the docs, the next step is to convert them into embeddings and insert them in the Vector DB. I have used the OpenAI embedding function to get the embeddings. The Langchain function from_documents has been used to write the docs in Qdrant DB. The arguments of this function are:
docs-> The list of documents that we want to insert in the Vector DB.openAIEmbeddings()-> The OpenAI embedding function that gets document embeddings.url-> The Qdrant cloud cluster URL.prefer_grpc-> If true, it will use the GRPC protocol to connect with the DB.api_key-> The API key of the Qdrant DB cloud cluster.collection_name-> The Qdrant DB collection name where the data is inserted.
from langchain_community.vectorstores import Qdrant
from langchain_openai import OpenAIEmbeddings
def insert_data_to_vector_store(docs):
qdrant = Qdrant.from_documents(
docs,
OpenAIEmbeddings(),
url=QDRANT_URL,
prefer_grpc=True,
api_key=QDRANT_API_KEY,
collection_name=VECTOR_DB_COLLECTION,
)
So far, we've explored three functions:
The first one is for organizing our data into chunks.
The next one is for labeling our data according to the department.
The third part involves inserting our data into the vector database.
Now, we require an orchestrator function that will sequentially call all these functions and manage the data. For that, I have written the insert_data_to_vector_store function. You can call this function multiple times to insert data from various departments, such as history and science.
def perform_data_insertion(department, file_name):
docs = chunk_data(file_name)
taggedDocs = tag_documents(docs, department)
insert_data_to_vector_store(taggedDocs)
perform_data_insertion(HISTORY_DEPARTMENT_NAME, "history_dept_data.txt")
perform_data_insertion(SCIENCE_DEPARTMENT_NAME, "science_dept_data.txt")
RAG Chatbot Demo
We've added basic authentication to our chatbot to identify the user interacting with it. Depending on the user, we'll retrieve their department and provide information relevant only to that department. I've set up two user profiles for bot access:
Emily from the Science department
Benjamin from the History department
Now, let's log in as Emily and chat with the bot. When you visit http://localhost:8502/, you'll initially see the login screen. There, I log in with the username "Emily."
The bot greets Emily with a text box below to chat.
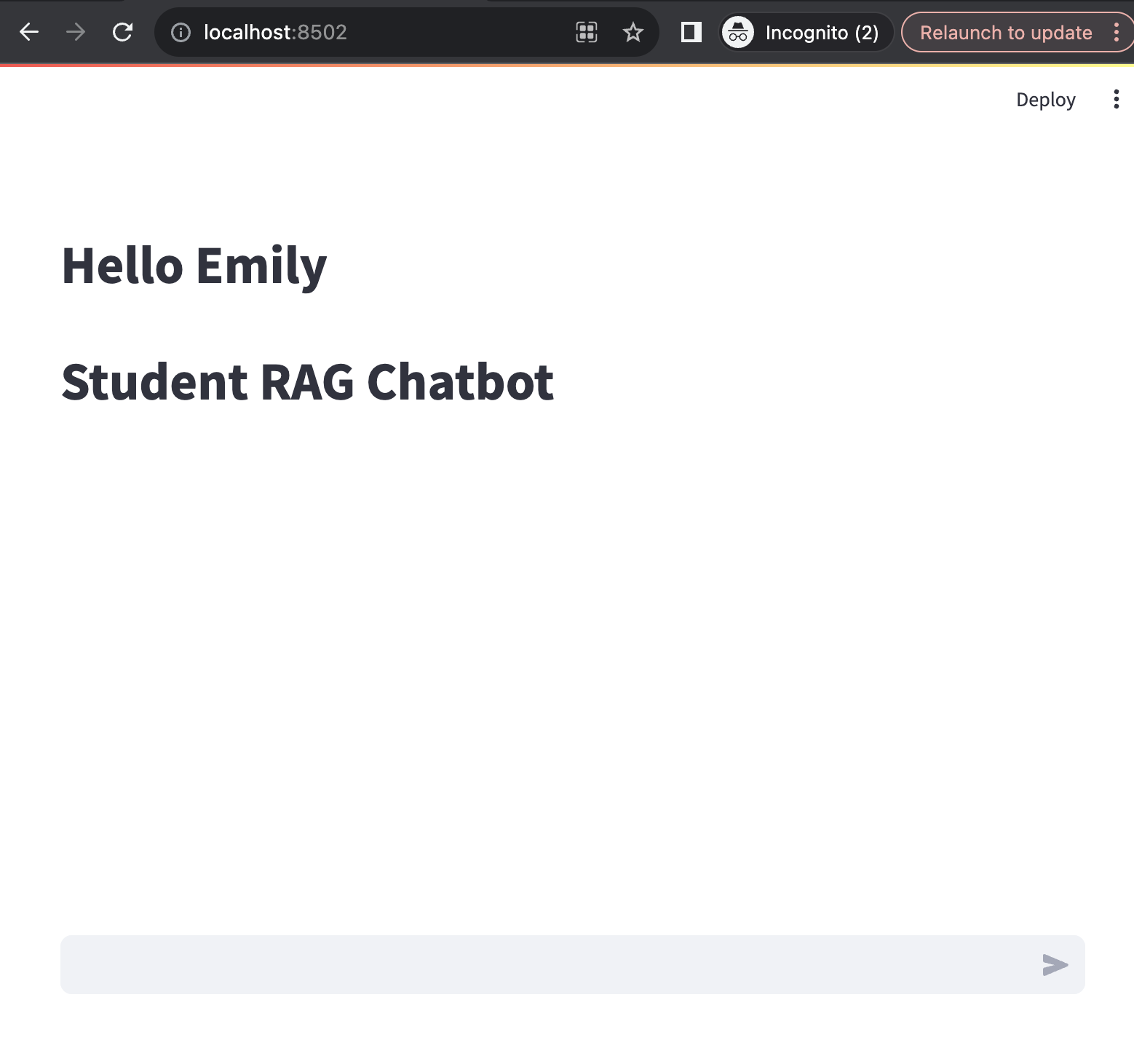
Querying Relevant Department Questions
Because I logged in as Emily, a science student, I'll start by asking the bot a few science questions. The bot first retrieved the semantically relevant document of those questions from Qdrant DB. It then used OpenAI to extract answers to those questions from the retrieved documents and display them to the user.
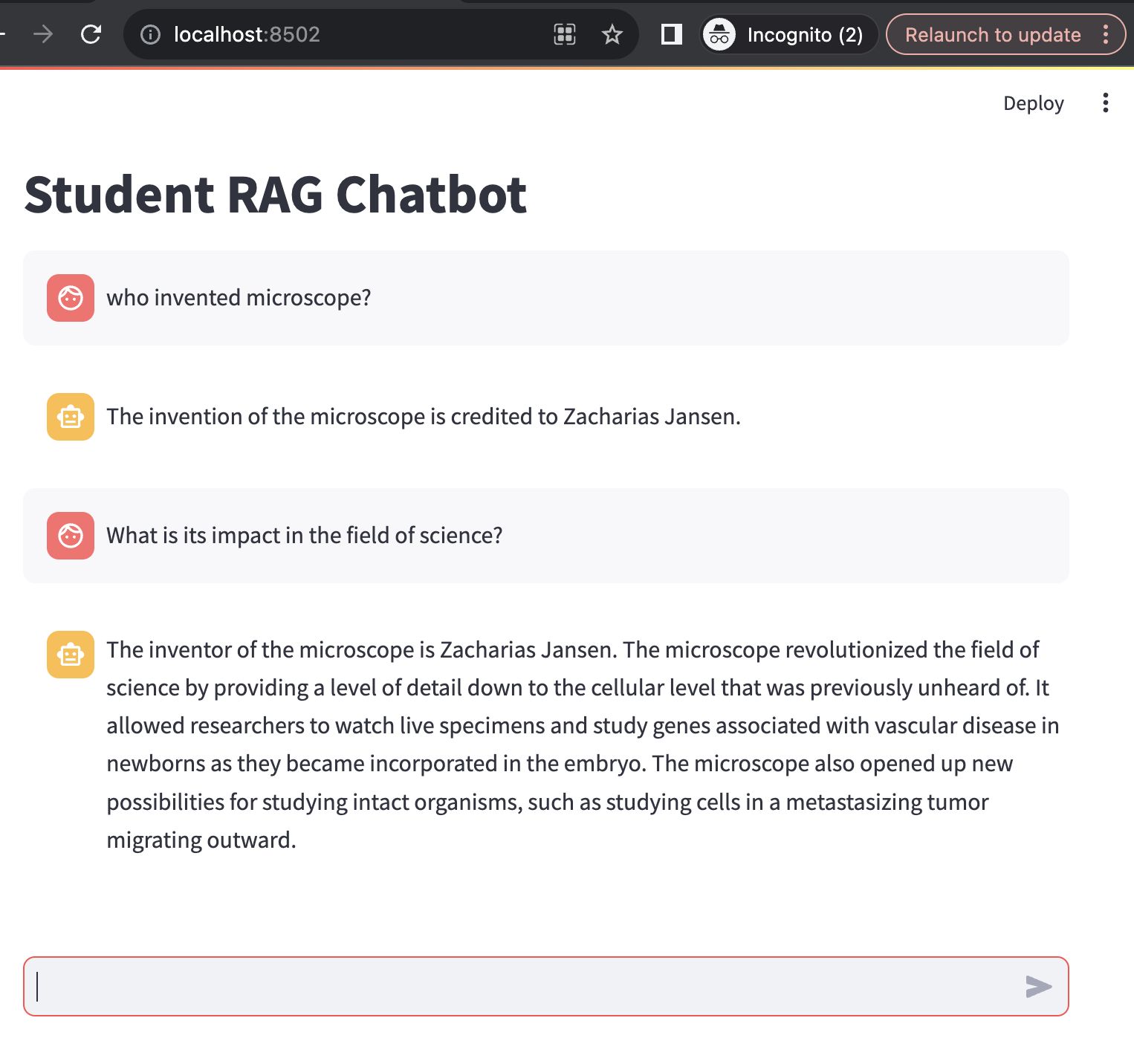
Below I have shared the logs which will help in better understanding the working of the bot. In the log, we can see that the original question
who invented microscope?
was formatted by the LLM and rewritten into
Who is credited with inventing the microscope?
Then the Vector DB is queried to fetch relevant vectors. The semantically closest vector is chosen and is passed to the LLM model to extract the answer.

For my second question:
What is its impact in the field of science?
The bot extracted the context from the chat history and grasped that we were seeking an answer regarding the impact of the inventor in the field of science. The bot then reformatted my question to:
What is the name of the inventor of the microscope and what impact has it had in the field of science?
Just like above, we again got 4 records and used the semantically closest vector document to answer the user’s question.

Querying Unrelated Department Questions
Now, let's observe what occurs when we pose a question outside of the science department, specifically a historical question. When I inquired about a historical topic:
Why was the Eiffel Tower build?
The bot replied with:
I don't have answer of this question.
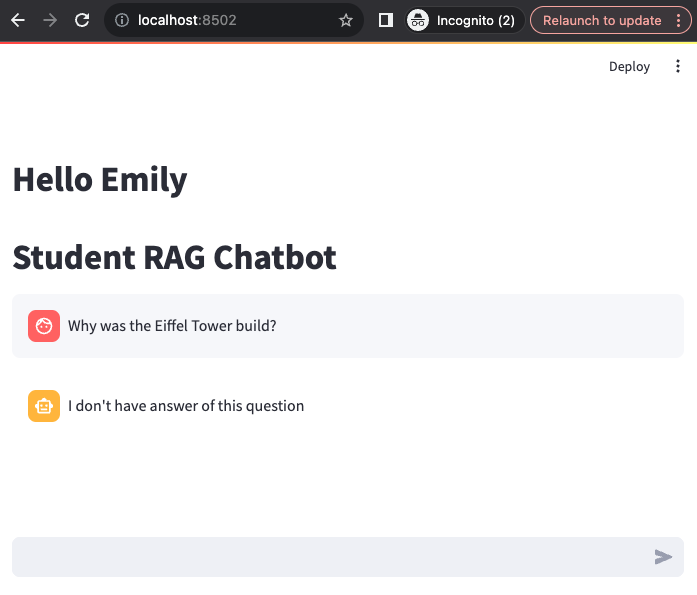
This is because the Vector DB didn't provide any relevant document that answers the historical question.
Let's check the logs to understand what happened behind the scenes. Since students from the science department don't have access to history department data, Qdrant DB returned a science vector that is semantically closest to the search query. However, since the vector doesn't contain the answer to that historical question, the LLM model couldn't extract the answer from the vector document.

Querying the Same Question from the Relevant Department
Now, I've logged in as Benjamin, a history student, to see if the bot can provide an answer to the question. This time, we observed that the bot successfully answered the question.
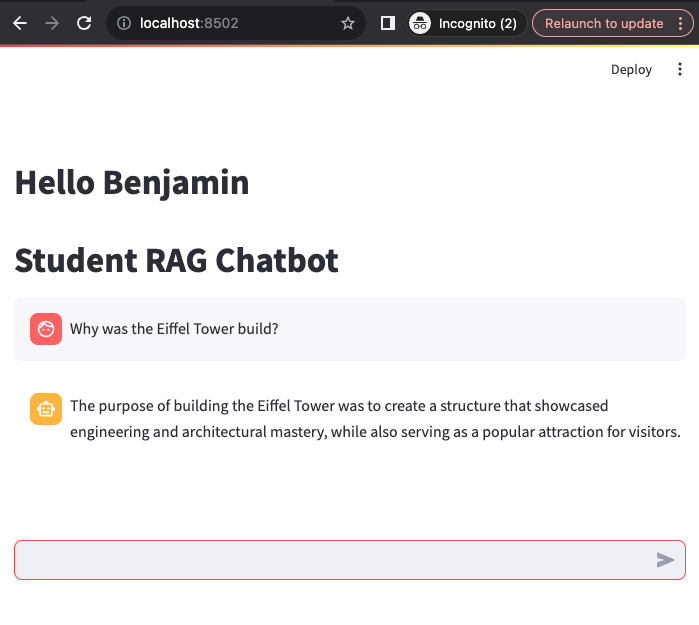
Here is the log of our query; this time the bot successfully retrieved the relevant history document from the vector database.

RAG Chatbot Internals
Now that we've gone through a brief demo of the chatbot, let's delve into the code to understand its functioning in detail. At a high level, our bot performs the following functions:
Processes the user input, chat history, and prompt template to form a more contextual question.
Uses the newly formed question to query the database and fetch semantically relevant vectors.
Sends the most semantically relevant vector document to an LLM model, along with the newly formed contextual question, to extract the answer from the document.
Forming a Better Contextual Question
Forming a better contextual question from the user message is done by the function query_generator_llm
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
from langchain.chains import LLMChain
from langchain_openai import OpenAI
@st.cache_resource
def query_generator_llm():
template = """Compose a question based on the provided user prompt
and conversation log to ensure the most pertinent information
is extracted from the knowledge base for the user's answer.
You are instructed to follow the below instructions when
generating the question:
- Prioritize the human input at all times, giving it precedence over the conversation log.
- Disregard any conversation log that does not directly pertain to the human input.
- Respond only when a question has been explicitly posed.
- Frame the question as a single sentence.
{chat_history}
{human_input}
"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history")
print("Instantiating query generator LLM chain with memory")
return LLMChain(
llm=OpenAI(),
prompt=prompt,
verbose=False,
memory=memory
)
I have written a basic prompt that instructs the LLM to go through the conversation log and the user input to frame a single-line question. I have used ConversationBufferMemory to store the history of the chat.
Querying Qdrant Vector Store
For querying the Qdrant vector store we will need a retriever; I have written the function to build the Qdrant retriever get_qdrant_retriever
import qdrant_client
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Qdrant
@st.cache_resource
def get_qdrant_retriever(department_name):
print("Creating retriever for department: ", department_name)
embeddings = OpenAIEmbeddings()
qdrantClient = qdrant_client.QdrantClient(
url=QDRANT_URL,
prefer_grpc=True,
api_key=QDRANT_API_KEY)
qdrant = Qdrant(qdrantClient, VECTOR_DB_COLLECTION, embeddings)
return qdrant.as_retriever(search_kwargs={'filter': {'group_id': department_name}})
Since we are querying the cloud instance of Qdrant DB, we need to pass the Qdrant cluster url and also the API key when building the Qdrant client.
qdrantClient = qdrant_client.QdrantClient(
url=QDRANT_URL,
prefer_grpc=True,
api_key=QDRANT_API_KEY)
Next, we have instantiated a Qdrant instance with 3 arguments: Qdrant client, collection name that will be queried, and the OpenAI Embedding function that will be used to convert the text question to embeddings.
qdrant = Qdrant(qdrantClient, VECTOR_DB_COLLECTION, embeddings)
And, finally, when initializing the retriever we pass the group filter as an argument. The group_id filter that we are passing here is responsible for partitioning the vectors based on the department name. This group_id filter makes sure that it retrieves only those documents that are tagged with the specified department name.
qdrant.as_retriever(search_kwargs={'filter': {'group_id': department_name}})
In the next function, I have used the retriever to fetch the documents from Qdrant DB. The Langchian function get_relevant_documents is used to fetch the documents from the vector DB. Out of a number of fetched records, we process only the first record which is semantically the closest vector to the query.
def get_docs_from_vector_store(formed_question, retriever):
print("LLM formed question: ", formed_question)
resultDocs = retriever.get_relevant_documents(formed_question)
print("Number of documents found: ", len(resultDocs))
if len(resultDocs) > 0:
retrieved_doc = resultDocs[0].page_content
print("Retrieved document: ", retrieved_doc)
return retrieved_doc
else:
print("No documents found")
return "No response"
Extracting Answers from Documents Using LLM
For extracting the answer from the document, I have written the function answer_questions
I have used a simple extraction prompt that instructs the LLM to answer the question using the provided document. If the answer is not present in the document, then simply reply that you don’t have the answer.
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
def answer_questions(document_data, formed_question):
template = """You are a question answering bot. You will be given
a QUESTION and a set of paragraphs in the CONTENT section. You need
to answer the question using the text present in the CONTENT section.
If the answer is not present in the CONTENT text then reply
`I don't have answer of this question`
CONTENT: {document}
QUESTION: {question}
"""
prompt = PromptTemplate(
input_variables=["document", "question"], template=template
)
print("Calling LLM to fetch answer of the question: ", formed_question)
llm_answer = LLMChain(
llm=ChatOpenAI(),
prompt=prompt,
verbose=False,
).run(document=document_data, question=formed_question)
print("Answer returned by LLM: ", llm_answer)
return llm_answer
Then I used the OpenAI LLM chain with the arguments document_data which is the retrieved document and formed_question which is the contextual question generated in the first step.
Putting It All Together
Now let's move to the final part of the code, where we put everything together.
if authenticate_user():
if "username" in st.session_state and "department" in st.session_state:
username = st.session_state["username"]
department = st.session_state["department"]
print("Found username and department in session: ", username, department)
st.title(f"Hello {username}")
# st.session_state["user"] = username
# st.session_state["department"] = department
department_name = st.session_state["department"]
query_generator_llm_chain = multitenancy_rag_chatbot.query_generator_llm()
qdrant_retriever = multitenancy_rag_chatbot.get_qdrant_retriever(department_name)
st.title("Student RAG Chatbot")
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Accept user input
if human_message := st.chat_input(""):
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": human_message})
# Display user message in chat message container
with st.chat_message("user"):
st.markdown(human_message)
# Display assistant response in chat message container
with st.chat_message("assistant"):
message_placeholder = st.empty()
# Form question based on the users last message and chat history
formed_question = query_generator_llm_chain.run(human_message)
# Fetch document from Vector store
relevant_doc = multitenancy_rag_chatbot.get_docs_from_vector_store(formed_question, qdrant_retriever)
# Send the fetched document from Vector store and the formed question to LLM to extract answer from the question
answer = multitenancy_rag_chatbot.answer_questions(relevant_doc, formed_question)
message_placeholder.markdown(answer)
st.session_state.messages.append({"role": "assistant", "content": answer})
Here first I am authenticating the user and then fetching the username and department of the user. The username and the department of the user are present in the Streamlit session state. Next, I have called the 2 functions query_generator_llm and get_qdrant_retriever to build the question generator LLM and the Qdrant retriever.
query_generator_llm_chain = multitenancy_rag_chatbot.query_generator_llm()
qdrant_retriever = multitenancy_rag_chatbot.get_qdrant_retriever(department_name)
The next few lines of the code is about the UI section that displays the chat messages in the UI. Another important piece of code in the above code block are the following:
formed_question = query_generator_llm_chain.run(human_message)
relevant_doc = multitenancy_rag_chatbot.get_docs_from_vector_store(formed_question, qdrant_retriever)
answer = multitenancy_rag_chatbot.answer_questions(relevant_doc, formed_question)
Here we ran the query_generator_llm_chain LLMChain which we have initiated above, to generate the contextual formatted question. Next, we have called get_docs_from_vector_store function that returned the most relevant document for our query from the Vector DB. And, finally, the answer_questions function is called to extract the answer from the document.
In conclusion, I trust that this blog has provided you with a comprehensive understanding of Multitenancy in Qdrant, elucidating its advantages and practical implementation. I am optimistic that the insights shared here will inspire you to explore the Multitenancy feature within your RAG chatbot project. All the code discussed about can be found in Github.
If you have any questions regarding the topic, please don't hesitate to ask in the comment section. I will be more than happy to address them. I regularly create similar content on Langchain, LLM, and AI topics. If you'd like to receive more articles like this, consider subscribing to my blog.
If you're in the Langchain space or LLM domain, let's connect on Linkedin! I'd love to stay connected and continue the conversation. Reach me at: linkedin.com/in/ritobrotoseth