LLM fine-tuning with instruction prompts


If you have ever tried to use the Mistral model from Hugging Face you will be provided with multiple options. Two of the most downloaded options are:
But what is the difference between these 2 models?
Mistral-7B-Instruct-v0.2 is an instruct fine-tuned version of Mistral-7B.
Instruction fine-tuning is a strategy used to improve the model’s performance on a variety of tasks like question answering, text classification, and text summarization.

How does instruction fine-tuning work?
Instruction fine-tuning involves training the LLM model using examples that demonstrate how it should respond to specific instructions. The process entails building a dataset of prompt completion examples for the desired task, each including an instruction.
For instance, if the goal is to improve summarization ability, examples starting with the instruction "Summarize the following" are included. Similarly, for enhancing classification skills, examples with instructions like "classify this sentence sentiment" are used.
These prompt completion examples enable the model to learn to generate responses that adhere to the given instructions. For generating the prompt completion examples, an instruction prompt template is used.
Instruction prompt template
An instruction prompt template is a reusable format for creating prompts that guide an LLM during instruction fine-tuning. It acts as a blueprint, defining the structure and components of prompts that effectively train the LLM to follow specific instructions.
The template typically follows a three-part structure:
Instruction: This specifies the action you want the LLM to perform. It's a clear and concise statement that tells the LLM what to do with the provided information.
{context}: This is a placeholder for the actual data the LLM needs to process to complete the task. It can be text, code, an image, or any other relevant information.
[OUTPUT]: This indicates the expected format of the LLM's response. It helps the LLM understand what kind of output is desired for the given instruction.
Task Fine-tuning
Fine-tuning for Question Answering task
Question-answering tasks return an answer for a given question.
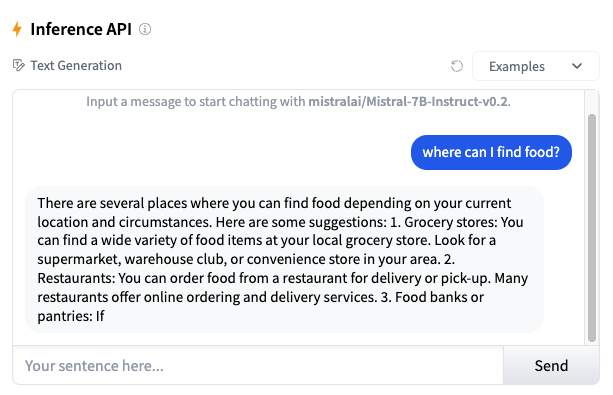
Dataset that can be used for question-answering training: Stanford Question Answering Dataset (SQuAD)
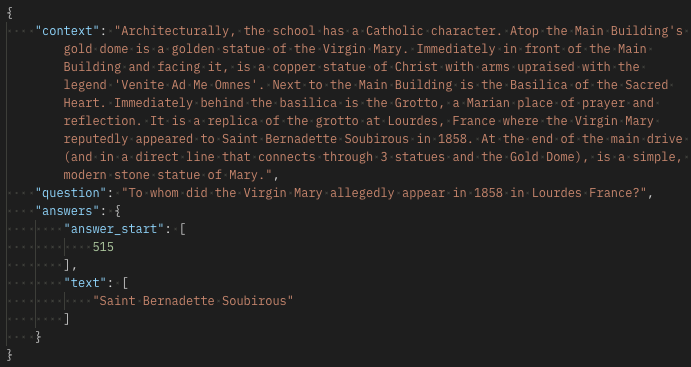
Explanation of the dataset columns:
context: background information from which the model needs to extract the answer.
question: the question a model should answer.
answers: the starting location of the answer token and the answer text.
The instruction prompt template for a question-answering task would be:
Answer the following question based on the passage: {context}
Question: {question}
[OUTPUT]: {answers}
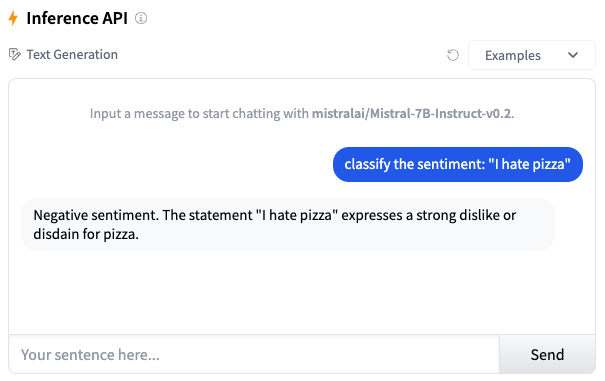
Fine-tuning for Text Classification task
Text classification, a fundamental task within Natural Language Processing (NLP), involves assigning a predefined label or class to a given text input. This includes tasks like categorizing text sentiment (positive, negative, or neutral).
The training dataset for sentiment analysis provides information indicating whether the sentiment of the text is positive or negative: Large Movie Review Dataset

Explanation of the dataset columns:
text: the movie review text.
label: a value that is either 0 for a negative review or 1 for a positive review.
The instruction prompt template for a text classification task would be:
Classify this sentence sentiment: {text}
[OUTPUT]: {label}
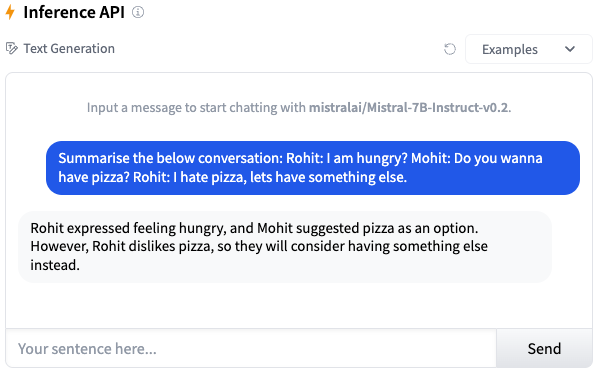
Fine-tuning for Text Summarization task
Summarization creates a shorter version of a document or an article that captures all the important information.
Dataset that can be used for Summarization task training: Summarization of US Congressional and California state bills
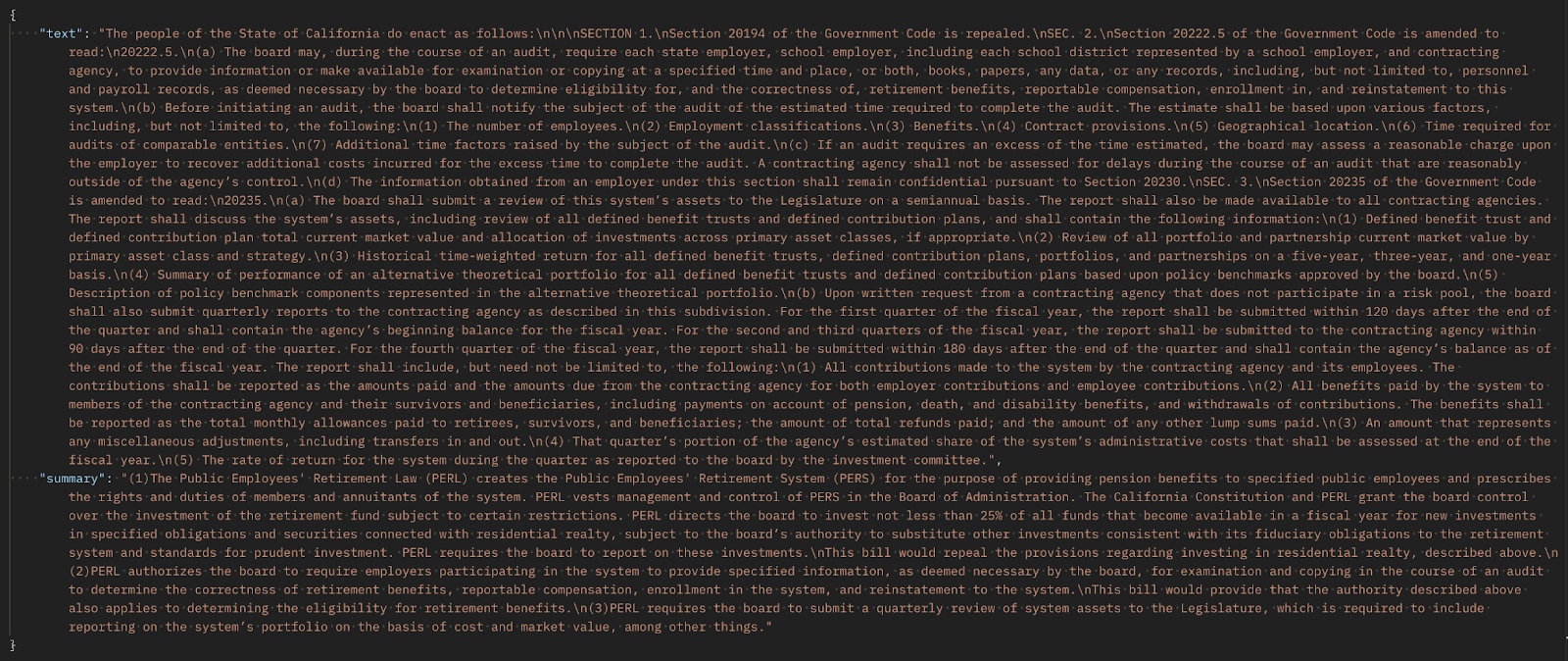
Explanation of the dataset columns:
text: the text which will be the input to the model.
summary: a condensed version of the text.
The instruction prompt template for a text summarization task would be:
Summarize the following passage: {text}
[OUTPUT]: {summary}
In this brief blog, I have endeavored to explain instruction fine-tuning with examples. I hope this aids in better understanding how instruction-based LLMs are trained.
I regularly create similar content on LangChain, LLMs, and related AI topics. If you'd like to read more articles like this, consider subscribing to my blog.
If you're in the Langchain space or LLM domain, let's connect on Linkedin! I'd love to stay connected and continue the conversation. Reach me at: linkedin.com/in/ritobrotoseth