
Building a Rental Apartment Search with Langchain's Self-Querying Retriever


In this blog post, we delve into the capabilities of Langchain's self-querying retriever, a powerful tool for bridging the gap between natural language and structured data retrieval. This retriever leverages a query-constructing LLM chain to transform a user's natural language query into a well-defined structured query. This structured query can then be used to apply filters to the search results based on the metadata attached to the vectors. So self-querying functionality gives us the ability to perform semantic similarity search along with the filtering capabilities offered by the vector store. Now we can not only identify documents based on their overall relevance to the user's query but also precisely filter results based on specific filtering conditions.
To illustrate the power of this approach, we'll embark on building a practical application using a RAG model. This RAG model will be specifically tailored to facilitate rental apartment searches. We will be using Qdrant as the vector store.
Adding Dataset for Retrieval
We commence by exploring the dataset. The Toronto Apartment Rental Price dataset serves as the primary data source for this application.
Before I used the data, I cleaned it up a bit. I removed the extra columns that weren't relevant and kept only the four pieces of information I cared about: number of bedrooms, number of bathrooms, address, and price. Furthermore, a data cleaning step was implemented to remove duplicate entries.
Following are the two utility functions for the same:
remove_csv_columns: This function facilitates the elimination of extraneous columns from CSV datasets.dedup_csv_content: This function addresses data redundancy by eliminating duplicate entries from the dataset.
import pandas as pd
def dedup_csv_content(file_name: str, unique_key_columns: list[str]):
# Load the CSV file into a DataFrame
df = pd.read_csv(file_name)
# Remove duplicate records based on unique key identifiers
df.drop_duplicates(subset=unique_key_columns, inplace=True)
# Save the unique records to a new CSV file
df.to_csv("unique_records.csv", index=False)
def remove_csv_columns(file_name: str, columns_to_remove: list[str]):
# Load the CSV file into a DataFrame
df = pd.read_csv(file_name)
# Remove the specified columns
df.drop(columns=columns_to_remove, inplace=True)
# Save the modified DataFrame to a new CSV file
df.to_csv("modified_records.csv", index=False)
remove_csv_columns("Toronto_apartment_rentals_2018.csv", ["Den", "Lat", "Long"])
dedup_csv_content("modified_records.csv", ["Bedroom", "Bathroom", "Address"])
Below is the snapshot of the dataset.

Next, we will write the data to Qdrant, below is the code for the same.
import os
import pandas as pd
from langchain_core.documents import Document
from langchain_core.embeddings import Embeddings
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Qdrant
collection_name = "apartment_collection"
QDRANT_URL = os.getenv("QDRANT_URL")
QDRANT_API_KEY = os.getenv("QDRANT_API_KEY")
# Read from the unique_records.csv file, then call the create_document function to create a document for each row
def read_csv_and_create_documents():
df = pd.read_csv("unique_records.csv")
# store the created documents in a list
documents = []
for index, row in df.iterrows():
document = create_document(
bedroom=row["bedroom"],
bathroom=row["bathroom"],
address=row["address"],
price=row["price"]
)
documents.append(document)
return documents
def create_document(bedroom: int, bathroom: float, address: str, price: str):
template = """This apartment has {bedroom} bedrooms and {bathroom} bathrooms. The address of the apartment is "{address}" and the monthly rent is {price}."""
final_text = template.format(bedroom=bedroom, bathroom=float_to_str(bathroom), address=address, price=price)
return Document(
page_content=final_text,
metadata={
"bedroom": bedroom,
"bathroom": float_to_str(bathroom),
"price": price_float_value(price)
}
)
def float_to_str(float_number):
if int(float_number) == float_number:
return str(int(float_number))
else:
return str(float_number)
def price_float_value(string_value):
cleaned_string = string_value.replace("$", "").replace(",", "")
return float(cleaned_string)
def insert_data_to_vector_store(docs, collection_name: str, embeddings: Embeddings):
"""
This method inserts the documents into the Qdrant vector store.
:param docs:
:param collection_name:
:param embeddings:
:return:
"""
Qdrant.from_documents(
docs,
embeddings,
url=QDRANT_URL,
prefer_grpc=True,
api_key=QDRANT_API_KEY,
collection_name=collection_name,
)
print("Data inserted successfully")
rent_apartment_docs = read_csv_and_create_documents()
insert_data_to_vector_store(rent_apartment_docs, collection_name, OpenAIEmbeddings())
The create_document function is responsible for creating Documents. For the page_content embedding variable, we have formed a template that contains the apartment details in the form of a string. Following is the template we are using:
"""This apartment has {bedroom} bedrooms and {bathroom} bathrooms.
The address of the apartment is "{address}" and the monthly rent
is {price}."""
In the metadata of theDocument, we are storing the bedroom, bathroom, and price information. These fields will be later used to apply filters to the search results.
There are a couple of things to note here:
We are not setting the address as metadata because applying a filter on the address will compare the entire address in the vector store document with the address in the user’s query. This approach is not ideal because the user might enter a partial address in the query; for example, only the street name where he is looking for the apartment. So it's better to use the address in the query field and perform a semantic search. Although Qdrant DB does support substring search for text fields I was not sure if Langchain would be able to translate it into the correct substring match condition. So to keep it simple I have kept the address out of the filter search.
The price field in the dataset was of type string, it is converted to float to be able to apply a filter on the price range.
The bathroom field is of type float since some of its values are in fractions. When filtering based on the user’s query, for some reason it was not able to filter the results correctly. This could be because the value stored in the vector’s metadata is in decimal like 1.0 and in the structured query the value was an integer. I couldn’t completely understand the reason why the filter was not working for float type, so to solve this issue I changed the type of this field to string.
The read_csv_and_create_documents function generates a list of Documents from the CSV dataset. And the insert_data_to_vector_store function writes the documents to the Qdrant collection.
Let's look at a few records in the database.
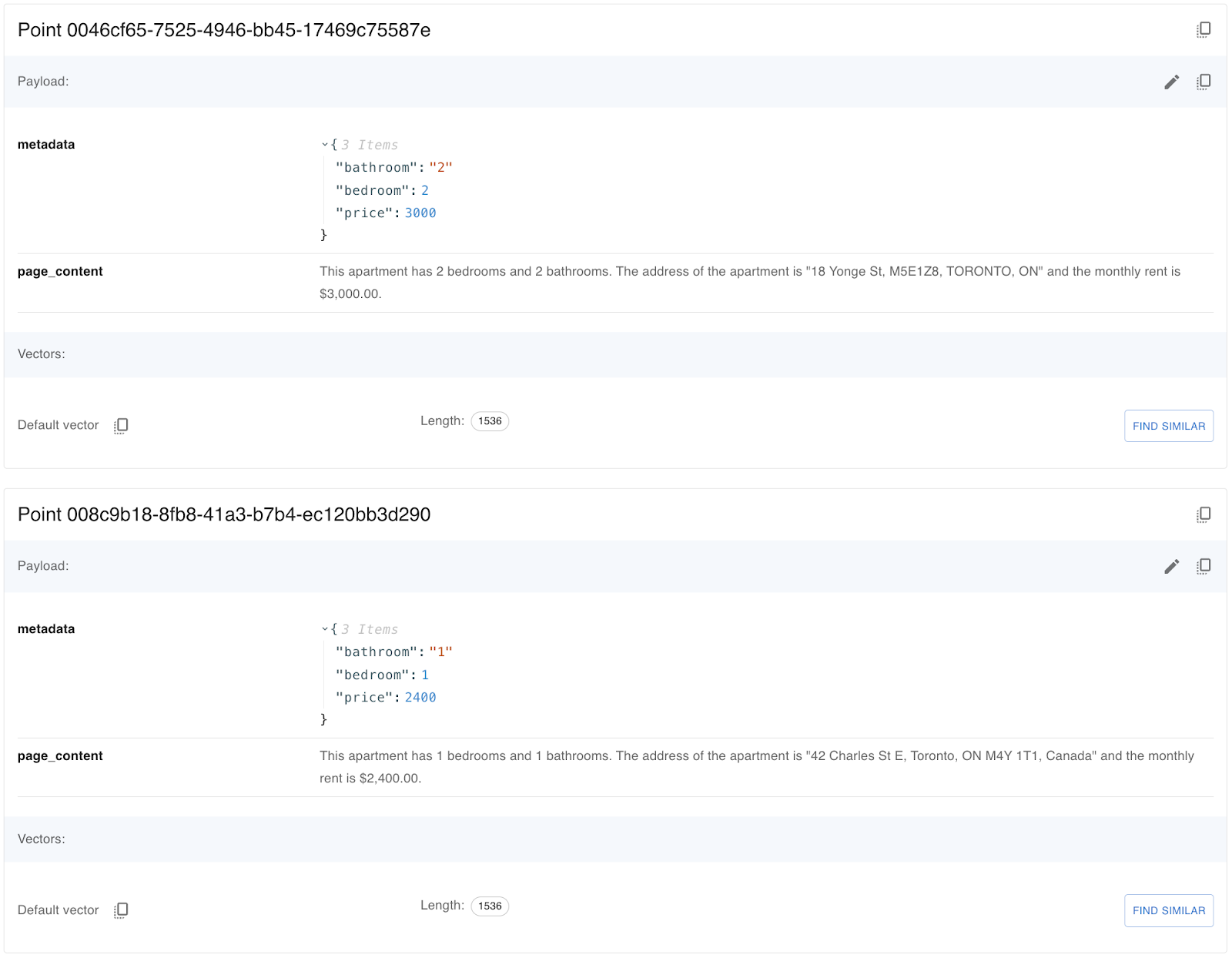
Understanding Qdrant filtering
Before diving into the Langchain structured query let's try to apply the filters directly to the Qdrant DB and see how it performs. Qdrant allows you to combine conditions in clauses. Clauses are different logical operations, such as OR, AND, and NOT. Clauses can be recursively nested into each other to reproduce a boolean expression.
An example of an AND clause will be fetching the apartments that have 2 bedrooms and 1.5 bathrooms. For this use case, we need to implement the Must clause, which makes sure that all the conditions in the list are satisfied. To read more about Qdrant filtering we can refer to their official doc.
import os
from qdrant_client import models
import qdrant_client
from qdrant_client import QdrantClient
QDRANT_URL = os.getenv("QDRANT_URL")
QDRANT_API_KEY = os.getenv("QDRANT_API_KEY")
def get_qdrant_client() -> QdrantClient:
"""
This method returns the Qdrant client object.
"""
return qdrant_client.QdrantClient(
url=QDRANT_URL,
prefer_grpc=True,
api_key=QDRANT_API_KEY)
client = get_qdrant_client()
def must_clause_example_1():
must_filter = models.Filter(
must=[
models.FieldCondition(
key="metadata.bedroom",
match=models.MatchValue(value=2),
),
models.FieldCondition(
key="metadata.bathroom",
match=models.MatchValue(value="1.5"),
)
]
)
retrieved_docs = client.scroll(
collection_name="apartment_collection",
scroll_filter=must_filter
)
print(retrieved_docs)
must_clause_example_1()
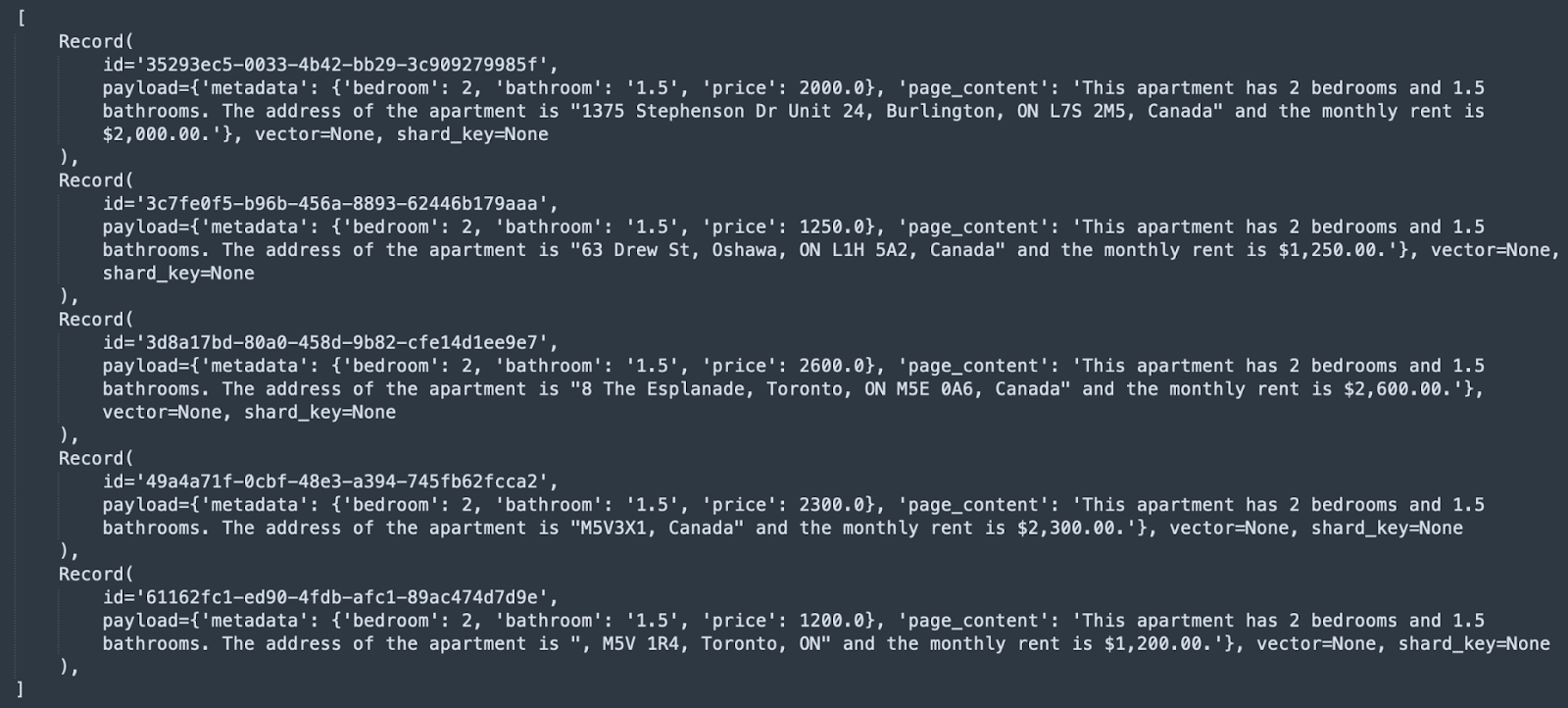
The function must_clause_example_1 creates an AND clause of 2 bedrooms and 1.5 bathrooms.
Running the query returned the following docs:
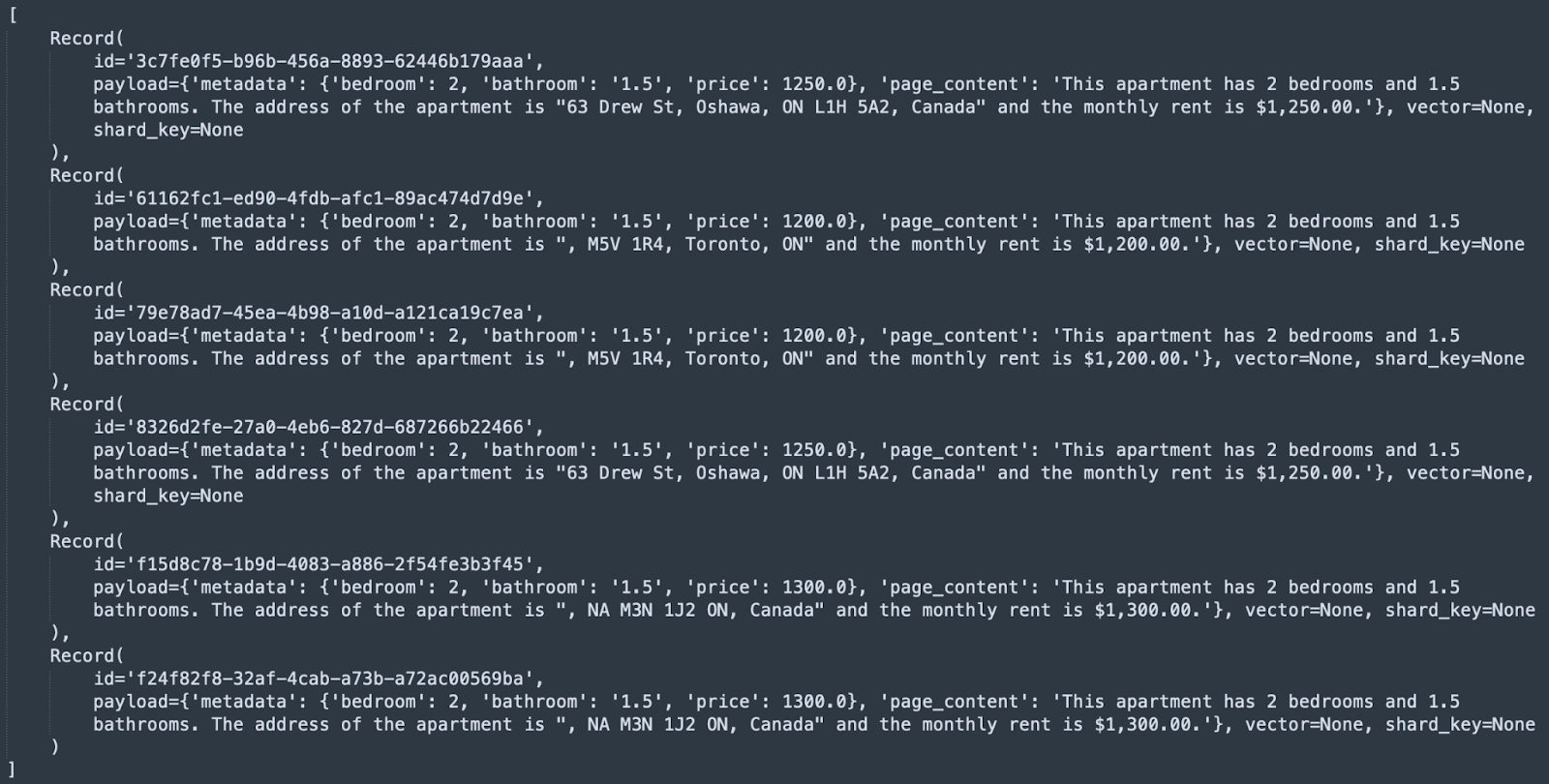
Now lets say we want to fetch the apartments that have 2 bedrooms and 1.5 bathrooms with monthly rent less than or equal to 1300 dollars. For implementing less than or greater than condition Qdrant provided us the range field option. Below is the query for the same:
def must_clause_example_2():
must_filter = models.Filter(
must=[
models.FieldCondition(
key="metadata.bedroom",
match=models.MatchValue(value=2),
),
models.FieldCondition(
key="metadata.bathroom",
match=models.MatchValue(value="1.5"),
),
models.FieldCondition(
key="metadata.price",
range=models.Range(
lt=None,
lte=1300,
)
)
]
)
retrieved_docs = client.scroll(
collection_name="apartment_collection",
scroll_filter=must_filter
)
print(retrieved_docs)
must_clause_example_2()
Running the query returned the following docs:
Building structured Query with Langchain
Now that we have a decent idea of how filtering works on vector metadata, let's try to understand how Langchain converts the natural language query to a structured query.
At a high level, this is the flow in which the natural language query is converted to a structured query.
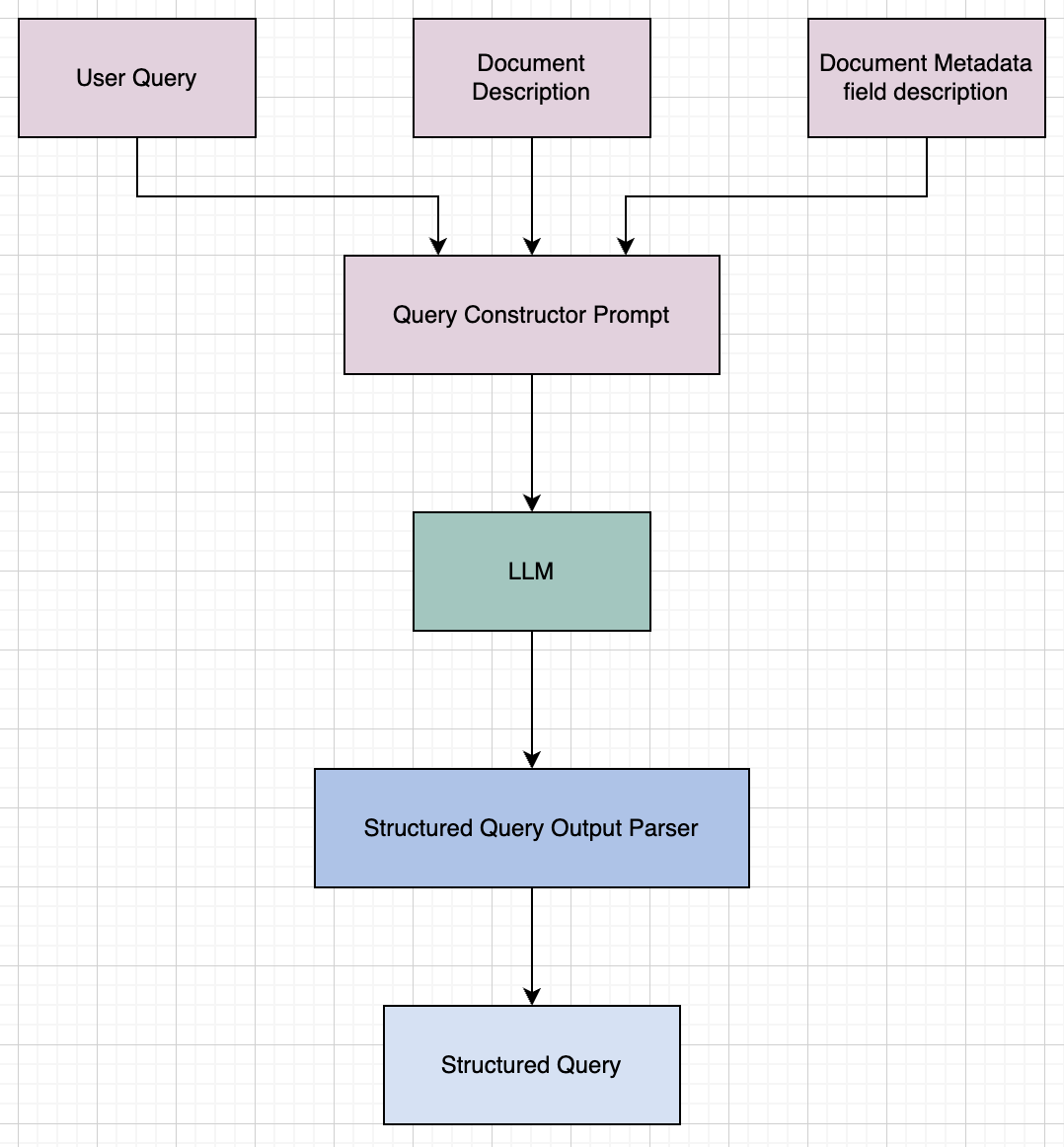
First, we create a Query constructor prompt that contains information like theuser query , the document content description, and the document metadata field description. The query constructor prompt is a FewShot Prompt that contains a few examples of structured query output from a natural language query.
The first part of the prompt contains the Structure Request Schema definition along with the instructions for building the structured request.
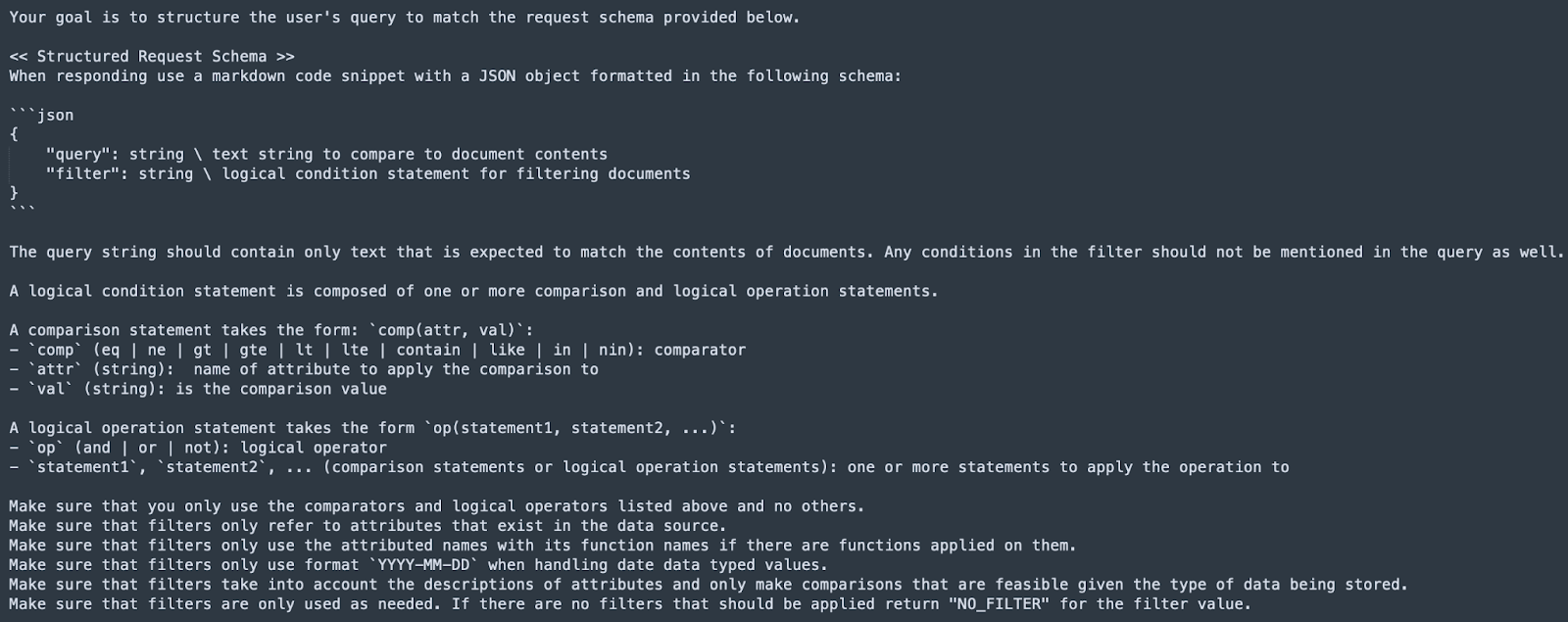
The second part of the Schema contains examples of structured queries from natural language queries.
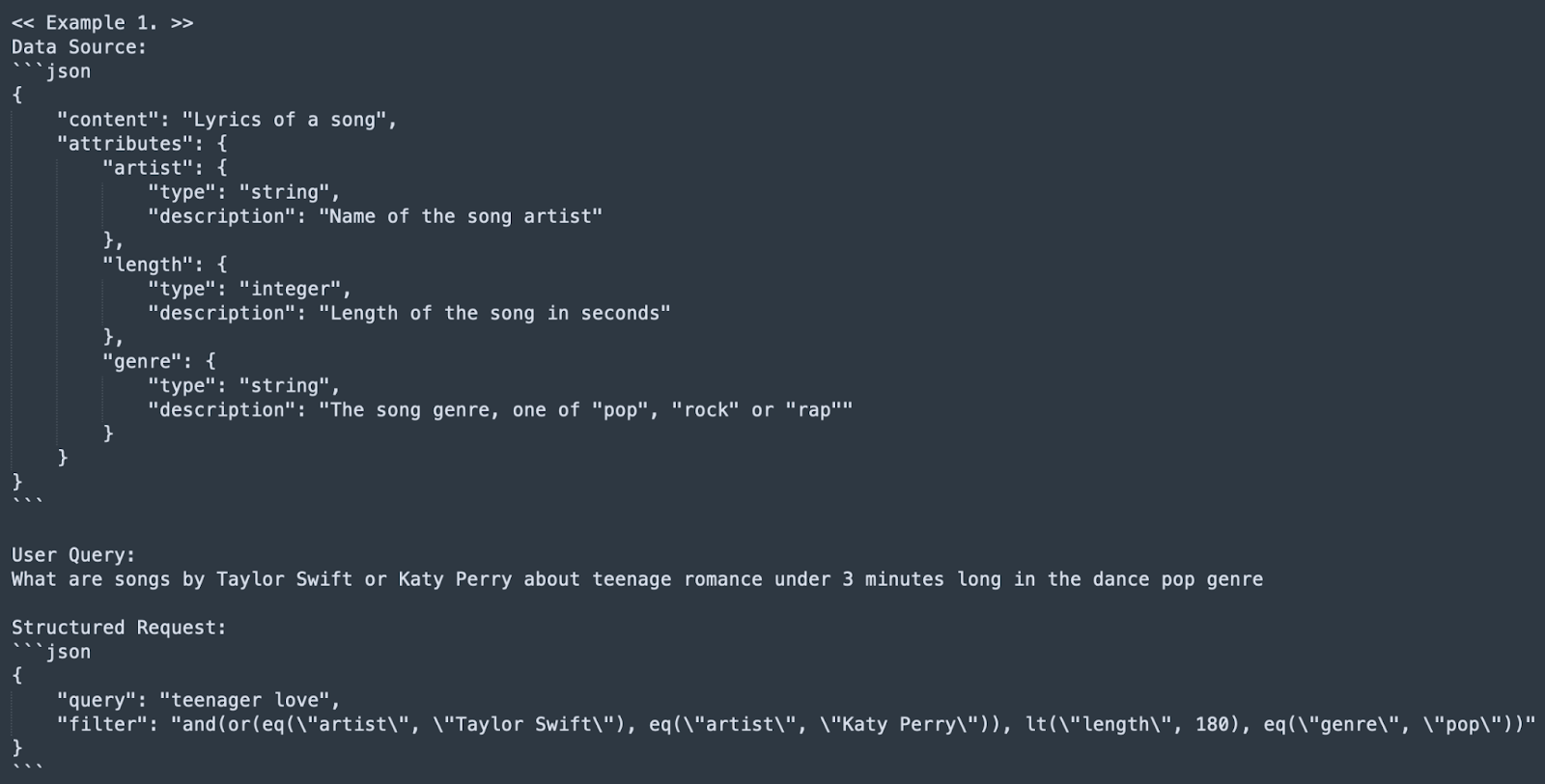
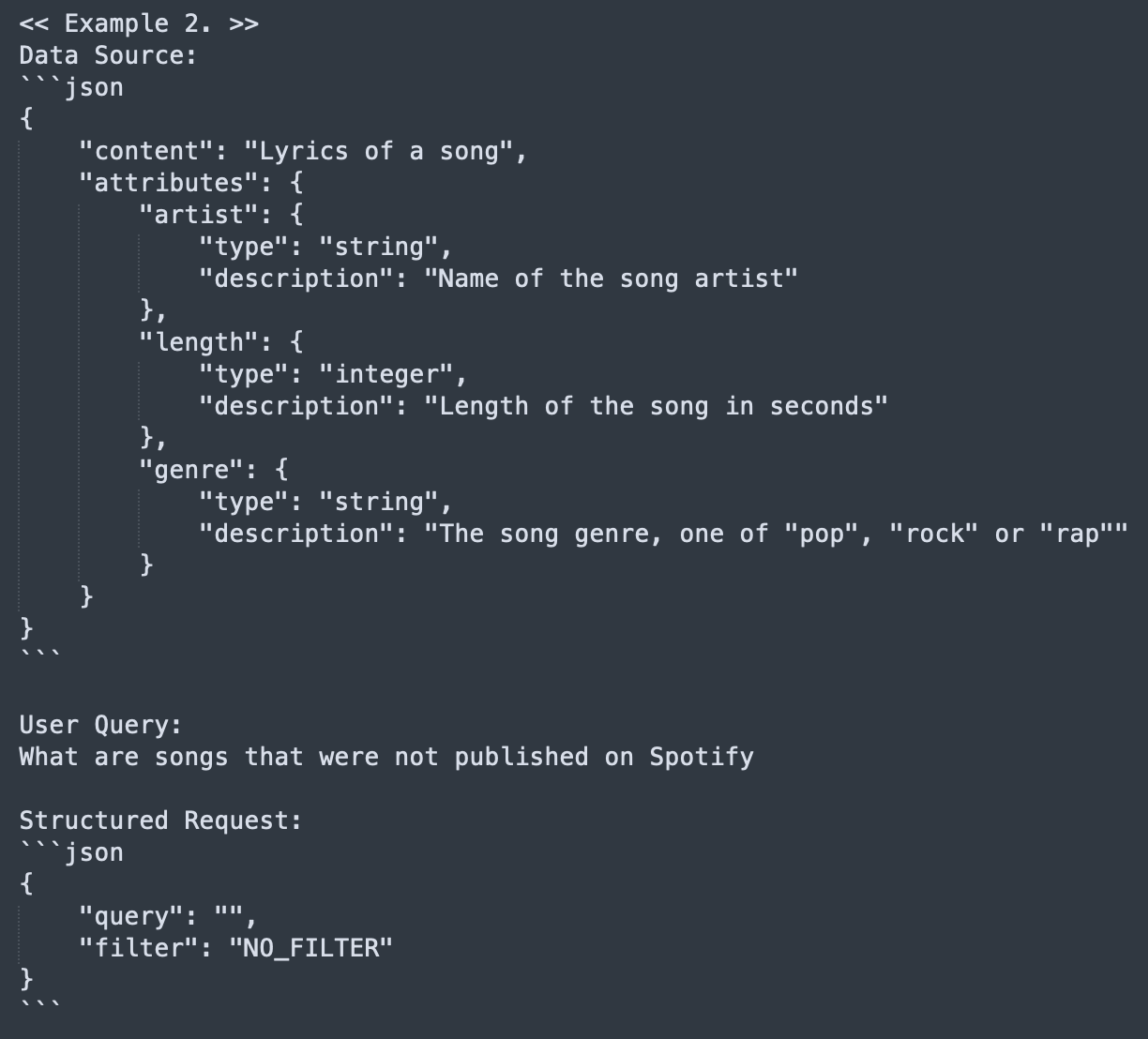
Post these examples, our document’s content description and metadata field descriptions are added to the prompt:

This few shot prompt is then passed to the LLM and it returns a structured query in response, for example for the below natural language query:
Find me a 2 bedroom and 1 bathroom apartment at Dufferin Street
The LLM responded with the below JSON:
{
"query": "Dufferin Street",
"filter": "and(eq(\"bedroom\", 2), eq(\"bathroom\", 2))"
}
The LLM response is then parsed by the StructuredQueryOutputParser which converts the JSON response to a StructuredQuery object.
{
"lc": 1,
"type": "not_implemented",
"id": [
"langchain",
"chains",
"query_constructor",
"ir",
"StructuredQuery"
],
"repr": "StructuredQuery(query='Dufferin Street', filter=Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='bedroom', value=2), Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='bathroom', value=2)]), limit=None)"
}
We have understood the process of how structured query is formed from natural language, now let's see the code implementation for the same.
First, we will define the document contents description and the attribute info of the metadata.
from langchain.chains.query_constructor.base import AttributeInfo
document_content_description = "Detailed description of the rented apartment"
attribute_info = [
AttributeInfo(
name="bedroom",
description="Number of bedrooms in the rented apartment.",
type="integer",
),
AttributeInfo(
name="bathroom",
description="Number of bathrooms in the rented apartment.",
type="string",
),
AttributeInfo(
name="price", description="The monthly rent of the apartment", type="float"
),
]
Next, we will build the structure query prompt, the get_query_constructor function is responsible for the same.
from langchain.chains.query_constructor.base import (
get_query_constructor_prompt, StructuredQueryOutputParser
)
from langchain_openai import ChatOpenAI
def get_query_constructor():
prompt = get_query_constructor_prompt(document_content_description, attribute_info)
output_parser = StructuredQueryOutputParser.from_components()
query_constructor = prompt | llm | output_parser
return query_constructor
Now let's execute the query constructor to check if the structured requests are getting built as expected or not.
user_query = "Find me a 2 bedroom and 1 bathroom apartment at Dufferin Street"
query_constructor = get_query_constructor()
structured_query = query_constructor.invoke({"query": user_query})
print(structured_query)
Following is the structured query it returns:
query='Dufferin Street'
filter=Operation(operator=<Operator.AND: 'and'>,
arguments=[
Comparison(comparator=<Comparator.EQ: 'eq'>,
attribute='bedroom', value=2),
Comparison(comparator=<Comparator.EQ: 'eq'>,
attribute='bathroom', value=1)]) limit=None
There is an issue with this structured query! On looking closely we see that the value of the bathroom attribute is an integer even though we have defined it as a string in the attribute_info. The LLM missed the bathroom datatype defined in attribute_info resulting in treating the value as an Integer.
If this query_constructor is executed by the SelfQueryRetriever, it won’t be able to fetch documents from the vector store because of the type mismatch. To solve this problem we need to explicitly highlight the field type of OpenAI and this can be done by providing an apartment query example in the few shot prompt.
Here is how I have solved this issue:
from langchain.chains.query_constructor.base import (
get_query_constructor_prompt, StructuredQueryOutputParser
)
from langchain_openai import ChatOpenAI
def get_query_constructor():
input_output_pairs = [
(
"Find me a 2 bedroom and 1 bathroom apartment at Yonge St",
{
"query": "Yonge St",
"filter": "and(eq(\"bedroom\", 2), eq(\"bathroom\", \"1\"))"
}
)
]
prompt = get_query_constructor_prompt(document_content_description, attribute_info, examples = input_output_pairs)
output_parser = StructuredQueryOutputParser.from_components()
query_constructor = prompt | llm | output_parser
return query_constructor
user_query = "Find me a 2 bedroom and 1 bathroom apartment at Dufferin Street"
query_constructor = get_query_constructor()
structured_query = query_constructor.invoke({"query": user_query})
print(structured_query)
What changed in the above get_query_constructor function is the addition of a new example variable input_output_pairs. This example variable is passed to the get_query_constructor_prompt function, which adds it to the few-shot prompt. Because of this example in the prompt, the LLM is now able to identify the bathroom attribute value as a string. Below is the structured query it generated.
query='Dufferin Street'
filter=Operation(operator=<Operator.AND: 'and'>,
arguments=[
Comparison(comparator=<Comparator.EQ: 'eq'>,
attribute='bedroom', value=2),
Comparison(comparator=<Comparator.EQ: 'eq'>,
attribute='bathroom', value='1')]) limit=None
The final step is to use the query_constructor in the SelfQueryRetriever. In the below method get_apartments_with_structured_query I have instantiated SelfQueryRetriever; in the constructor, I have passed these attributes:
Query constructor
Qdrant vector store instance
QdrantTranslator, which converts the structured query into a Qdrant filter clause.
import os
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import OpenAIEmbeddings
from langchain.retrievers.self_query.qdrant import QdrantTranslator
from self_query_query_constructor_example import get_query_constructor
import qdrant_client
from langchain_community.vectorstores import Qdrant
from langchain_core.embeddings import Embeddings
from typing import Optional
from langchain_core.vectorstores import VectorStore
QDRANT_URL = os.getenv("QDRANT_URL")
QDRANT_API_KEY = os.getenv("QDRANT_API_KEY")
collection_name = "apartment_collection"
def get_qdrant_vectorstore(
embeddings: Embeddings,
collection_name: str,
content_payload_key: Optional[str] = "page_content") -> VectorStore:
"""
This method returns the Qdrant vector store object.
collection_name = "MyCollection"
vectorstore = get_qdrant_vectorstore(OpenAIEmbeddings(), collection_name)
"""
qdrantClient = qdrant_client.QdrantClient(
url=QDRANT_URL,
prefer_grpc=True,
api_key=QDRANT_API_KEY)
return Qdrant(qdrantClient, collection_name, embeddings, content_payload_key=content_payload_key)
def get_apartments_with_structured_query(user_query: str):
vectorstore = get_qdrant_vectorstore(OpenAIEmbeddings(), collection_name)
query_constructor = get_query_constructor()
retriever = SelfQueryRetriever(
query_constructor=query_constructor,
vectorstore=vectorstore, structured_query_translator=QdrantTranslator(metadata_key="metadata"),
)
return retriever.invoke(user_query)
Now let's execute the get_apartments_with_structured_query function to see the results.
test_query_1 = "Find me a 2 bedroom and 1 bathroom apartment at Dufferin Street"
print(get_apartments_with_structured_query(test_query_1))
This is the output we got:
[Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is "200 Dufferin Street, Toronto, ON,
M6K 1Z4" and the monthly rent is $2,230.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 2230.0}),
Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is "295 Dufferin St., Toronto, ON, M6K 1Z6"
and the monthly rent is $2,574.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 2574.0}),
Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is "146 Dufferin St, Orangeville, ON L9W
1X2, Canada" and the monthly rent is $1,790.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 1790.0}),
Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is "2087 Duberry Dr, Pickering, ON L1X 1Y7,
Canada" and the monthly rent is $1,730.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 1730.0})]
Now let’s try another query:
test_query_2 = "Find me an apartment with 1 bathroom, 2 bedrooms and price less than 2200"
print(get_apartments_with_structured_query(test_query_2))
Following the output for the above query:
[Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is ", Toronto M5J 0B8 ON, Canada" and the
monthly rent is $1,500.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 1500.0}),
Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is ", Toronto M5B 2K3 ON, Canada" and the
monthly rent is $1,200.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 1200.0}),
Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is ", Toronto m5a0j3 ON, Canada" and the
monthly rent is $2,000.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 2000.0}),
Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is ", M5J 3A3, Toronto, ON, Canada" and
the monthly rent is $1,180.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 1180.0})]
Let's try a final complicated one:
test_query_3 = "2 bedrooms and 1 bathroom apartment at Dufferin Street and price less than 2200"
print(get_apartments_with_structured_query(test_query_3))
This is the output of the above query:
[Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is "146 Dufferin St, Orangeville, ON L9W
1X2, Canada" and the monthly rent is $1,790.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 1790.0}),
Document(page_content='This apartment has 2 bedrooms and 1 bathrooms.
The address of the apartment is "2087 Duberry Dr, Pickering, ON L1X 1Y7,
Canada" and the monthly rent is $1,730.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 1730.0}),
Document(page_content='This apartment has 2 bedrooms and 1 bathrooms. The
address of the apartment is "4866 Bathurst Street, Toronto, ON, M2R 1X4"
and the monthly rent is $2,017.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 2017.0}),
Document(page_content='This apartment has 2 bedrooms and 1 bathrooms. The
address of the apartment is "4190 Bathurst Street, Toronto, ON, M3H 3P9"
and the monthly rent is $2,177.00.',
metadata={'bedroom': 2, 'bathroom': '1', 'price': 2177.0})]
I hope this blog gave you a better understanding of how Langchain's Self-Querying Retriever works. If you have any questions regarding the topic, please don't hesitate to ask in the comment section. I will be more than happy to address them.
I regularly create similar content on LangChain, LLMs, and AI-related topics. If you'd like to read more articles like this, consider subscribing to my blog.
If you're in the Langchain space or LLM domain, let's connect on Linkedin! I'd love to stay connected and continue the conversation. Reach me at: linkedin.com/in/ritobrotoseth